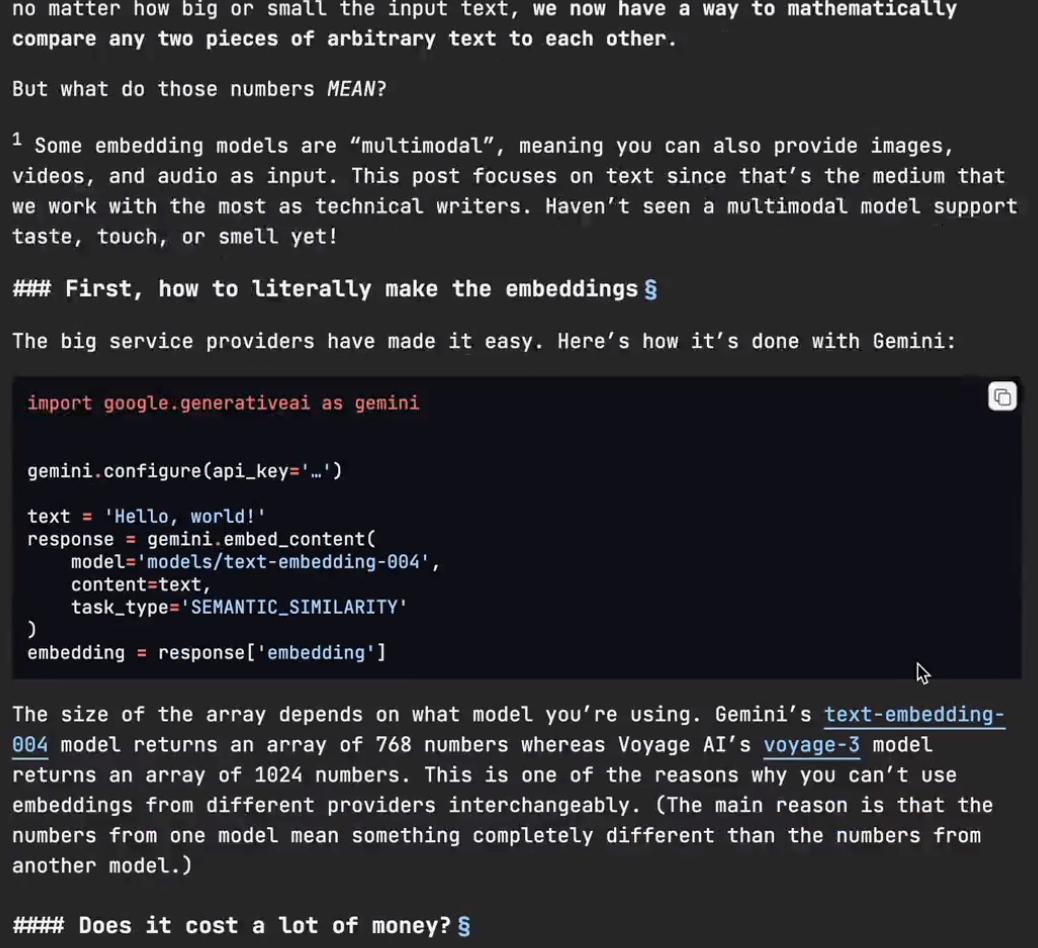
在大模型领域,很多人都听过Embedding(嵌入向量),但不清楚它到底是什么,这次就来讲明白—— 1、什么是Embedding? Embedding是把一段文本转换成一个数组,这个数组由几十到上千个数字组成,数字则可以看成是“语义空间”中的一个坐标点。 举个例子:你输入“Hello, world!” —— 模型返回 `[0.123, -0.987, …]` 这样的向量。 重要的是,不管你输入的是一句话,还是一篇文档,返回的嵌入向量维度固定,以让不同长度的文本可以直接进行比较。 2、嵌入向量号称“语义坐标”。 Embedding的空间是高维空间(768维、1024维起跳),里面每个点代表一段文本的“语义位置”。 - 距离越近,表示内容语义越相似; - 距离越远,说明内容语义越不相似。 比如经典例子: Embedding("king") - Embedding("queen") ≈ Embedding("man") - Embedding("woman") 这是模型自动学出来的语义结构,说明它“理解”了性别转换的概念。 3.、怎么生成Embedding? 现在各大平台都支持文本嵌入: - Google Gemini:`text-Embedding-004`(2048维) - OpenAI:`text-Embedding-3-large`(8192维) - Voyage AI:`voyage-3`(输入量大、1024维) 只要几行代码就能搞定,而且速度快、成本低。 4、Embedding能用在哪? Embedding不只是“表示文本”,它还在很多应用场景发挥作用: - 语义搜索:不再靠关键词,而是“意思相近”就能搜出来; - 智能推荐:比如技术文档中,找出当前页面语义上最接近的另一篇内容; - 自动分类/聚类:让机器自动理解内容主题,而不靠人工标签; - 知识图谱构建:用嵌入向量判断实体之间是否有关联。 5、Embedding被低估了。 生成式模型很炫,但Embedding是更底层、更通用的工具。它不直接生成内容,却帮你理解内容之间的关系,进行“信息压缩和对齐”。 对技术写作者、产品经理、开发者来说,它就像一个新维度的接口,让你能以结构化方式去描述和处理非结构化内容。 如果文档网站都开放内容的嵌入向量接口,社区便能基于它做出一批新的应用,内容不再只是“可读”,而是“可计算”。 嵌入向量,看起来只是一堆数字,其实背后藏着的是语义世界的地图。 感兴趣的小伙伴可以点击: