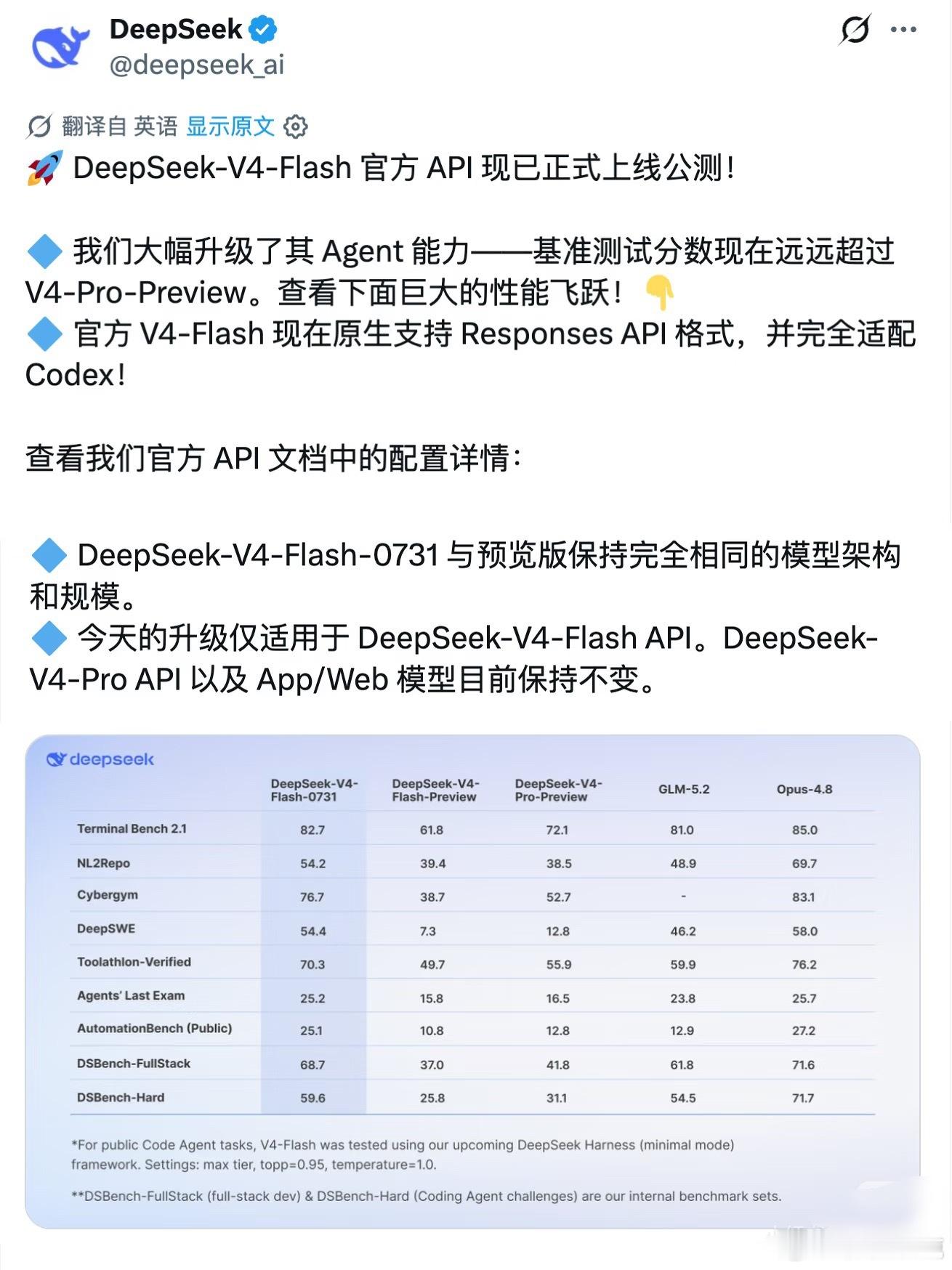
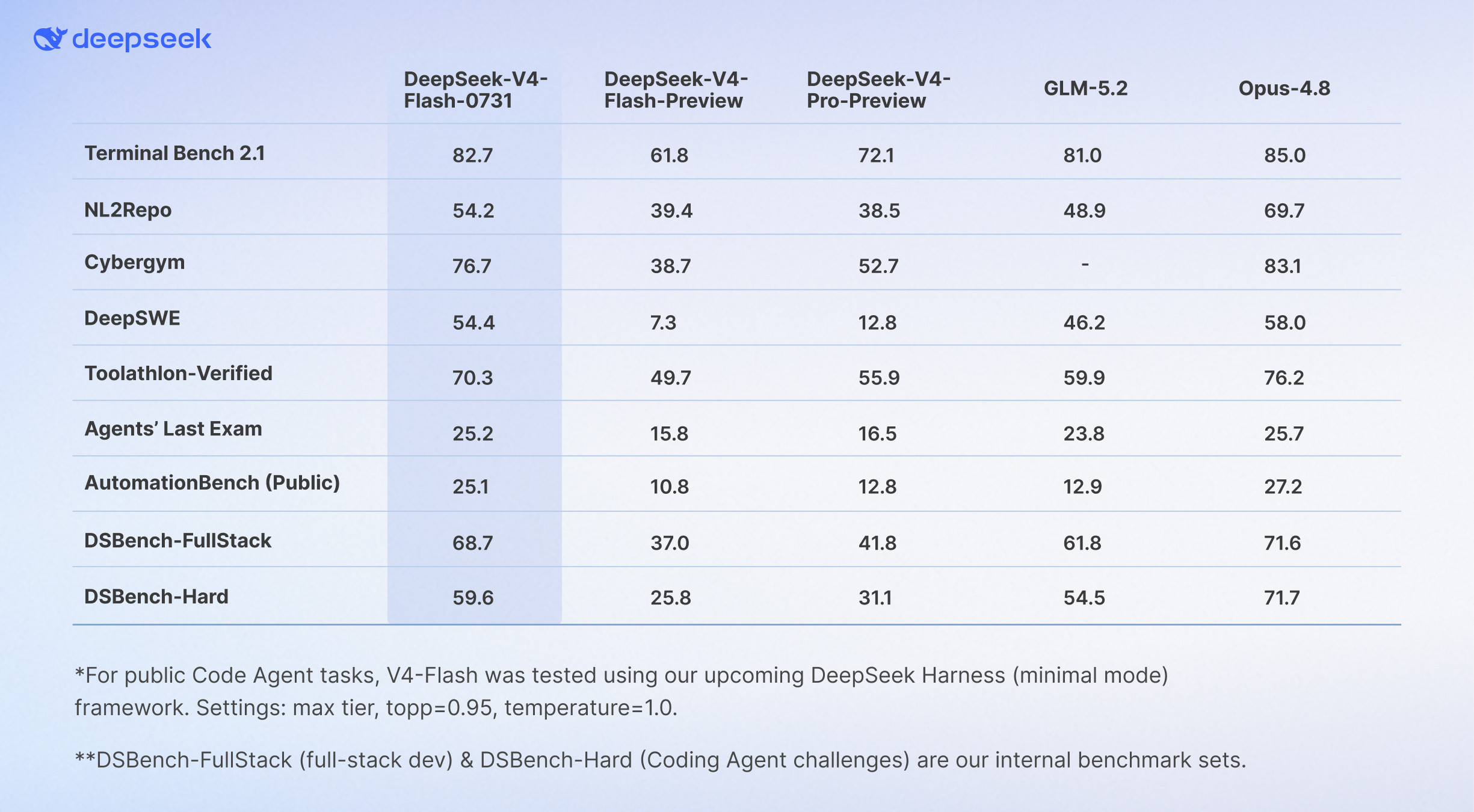
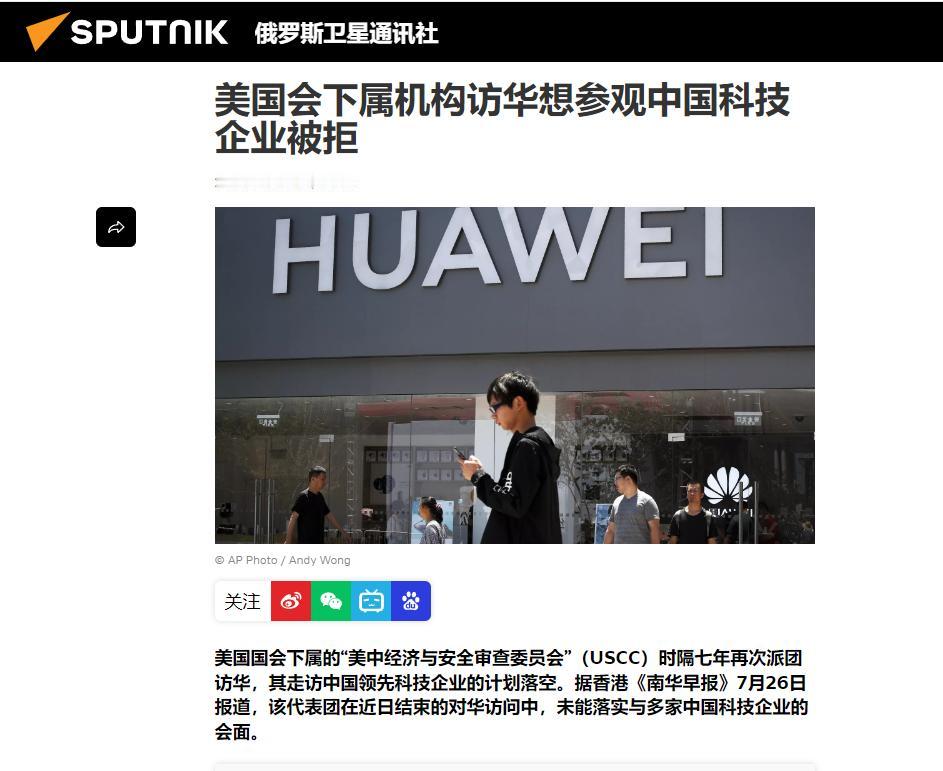
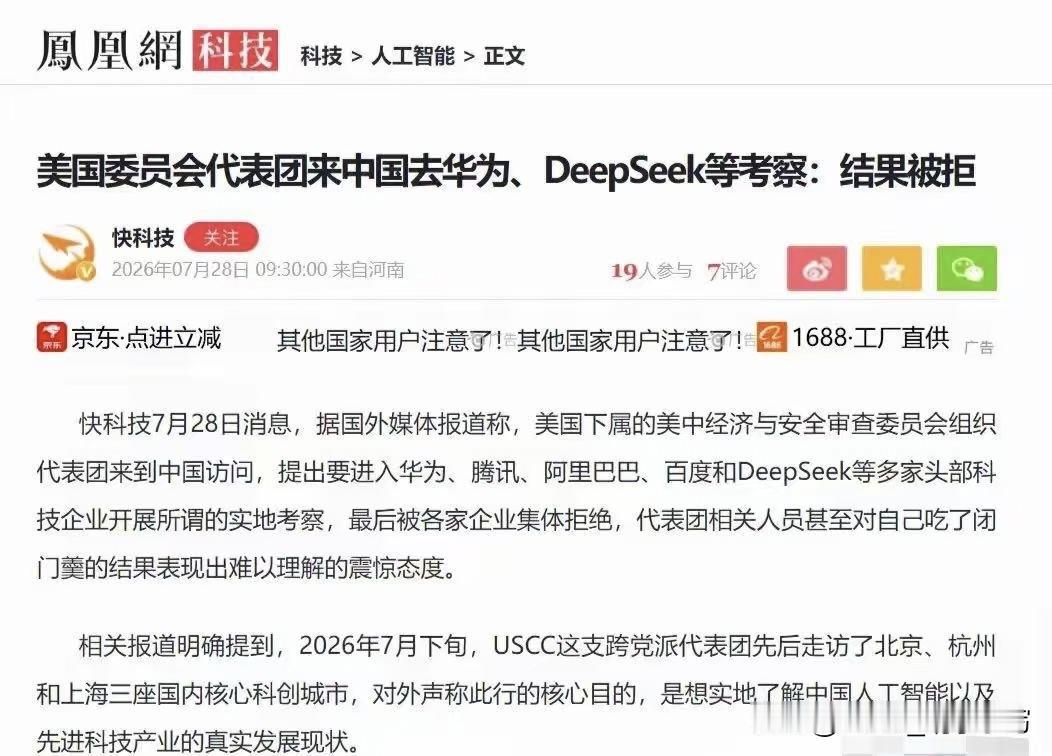
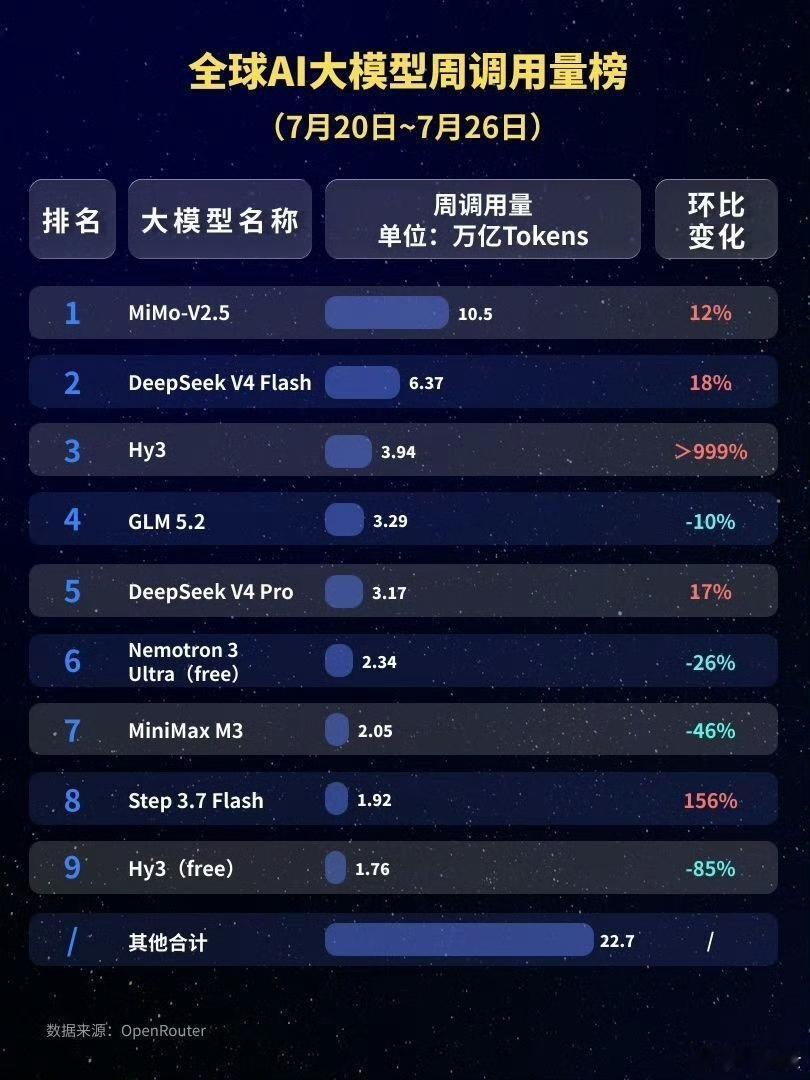
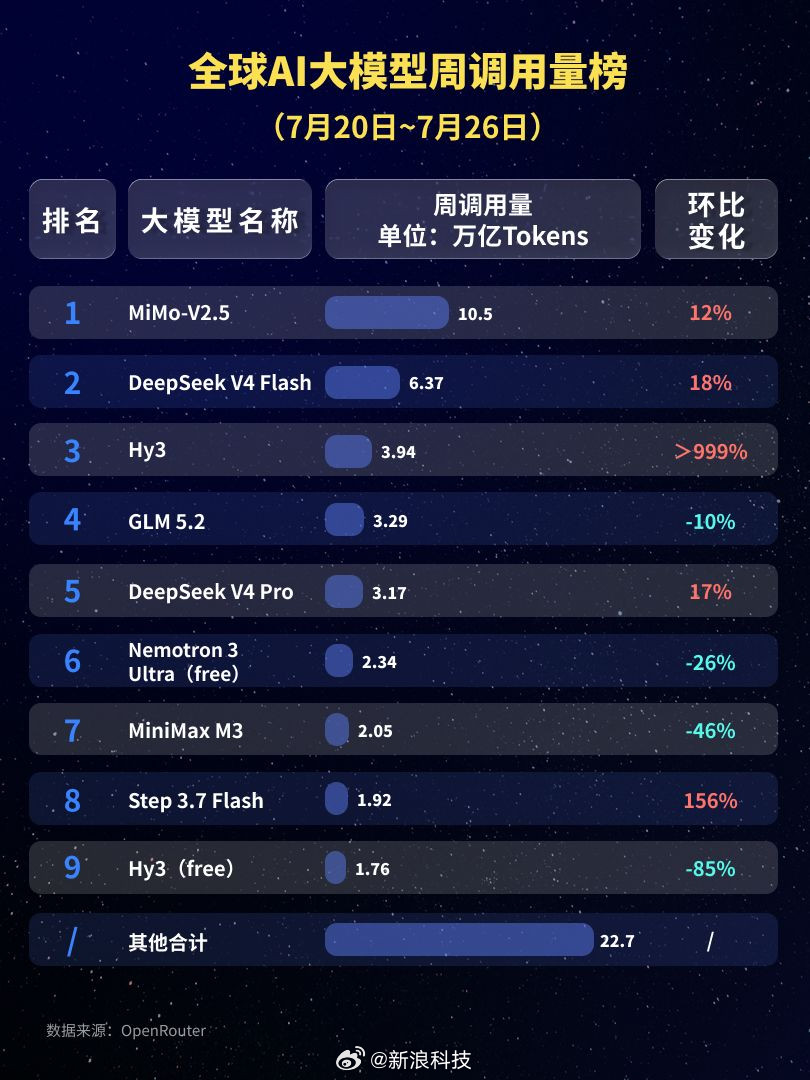
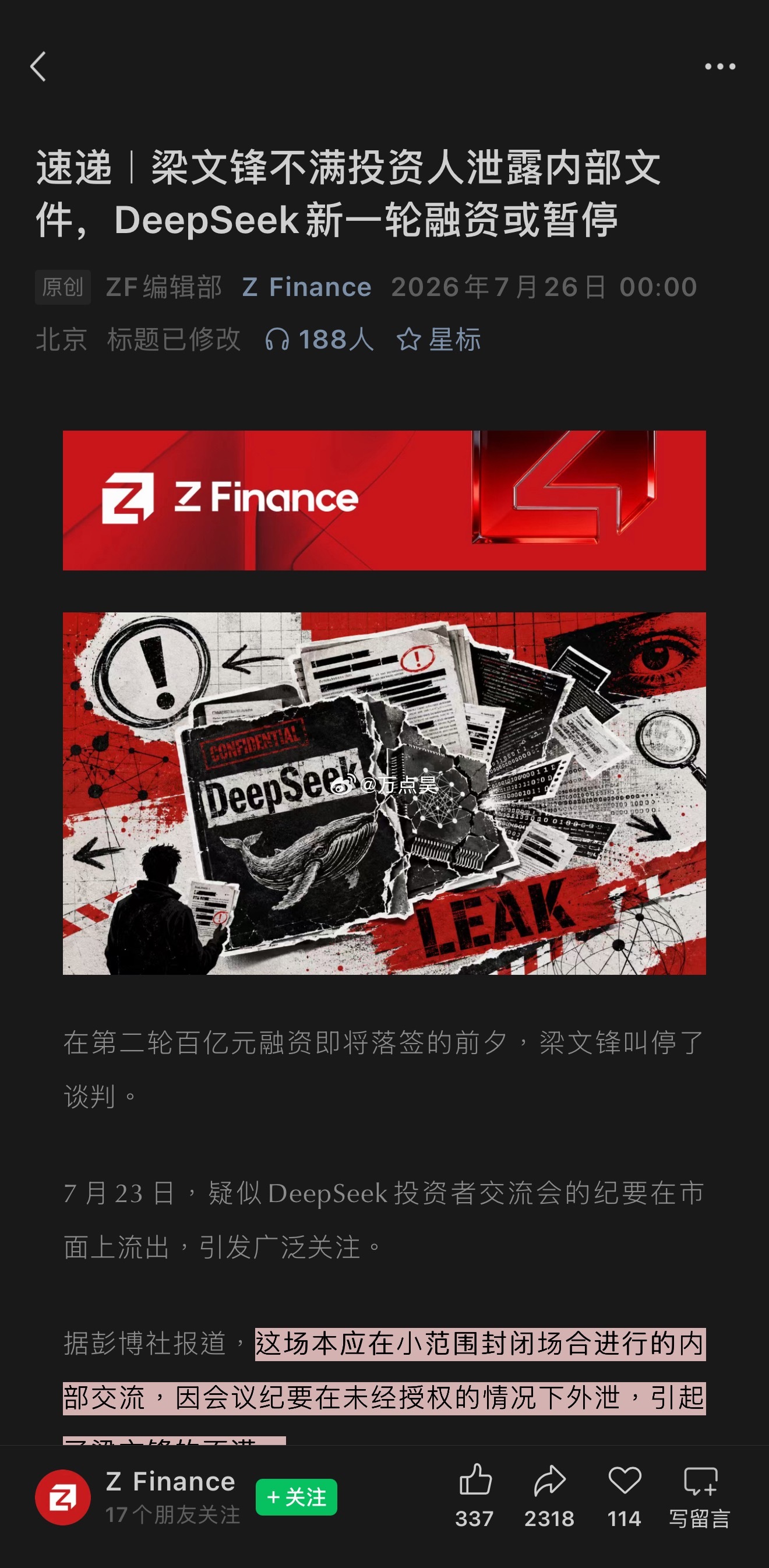
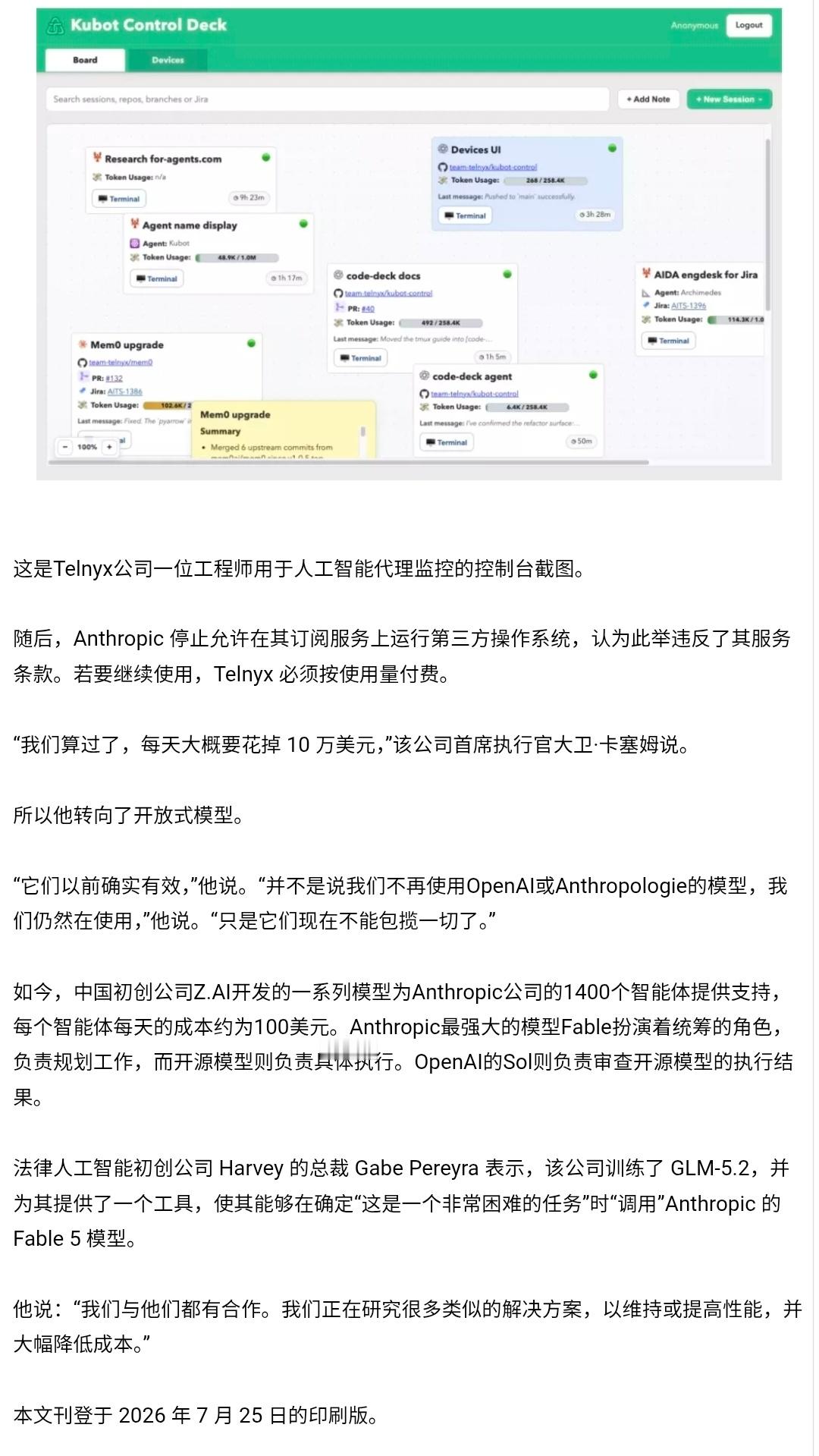
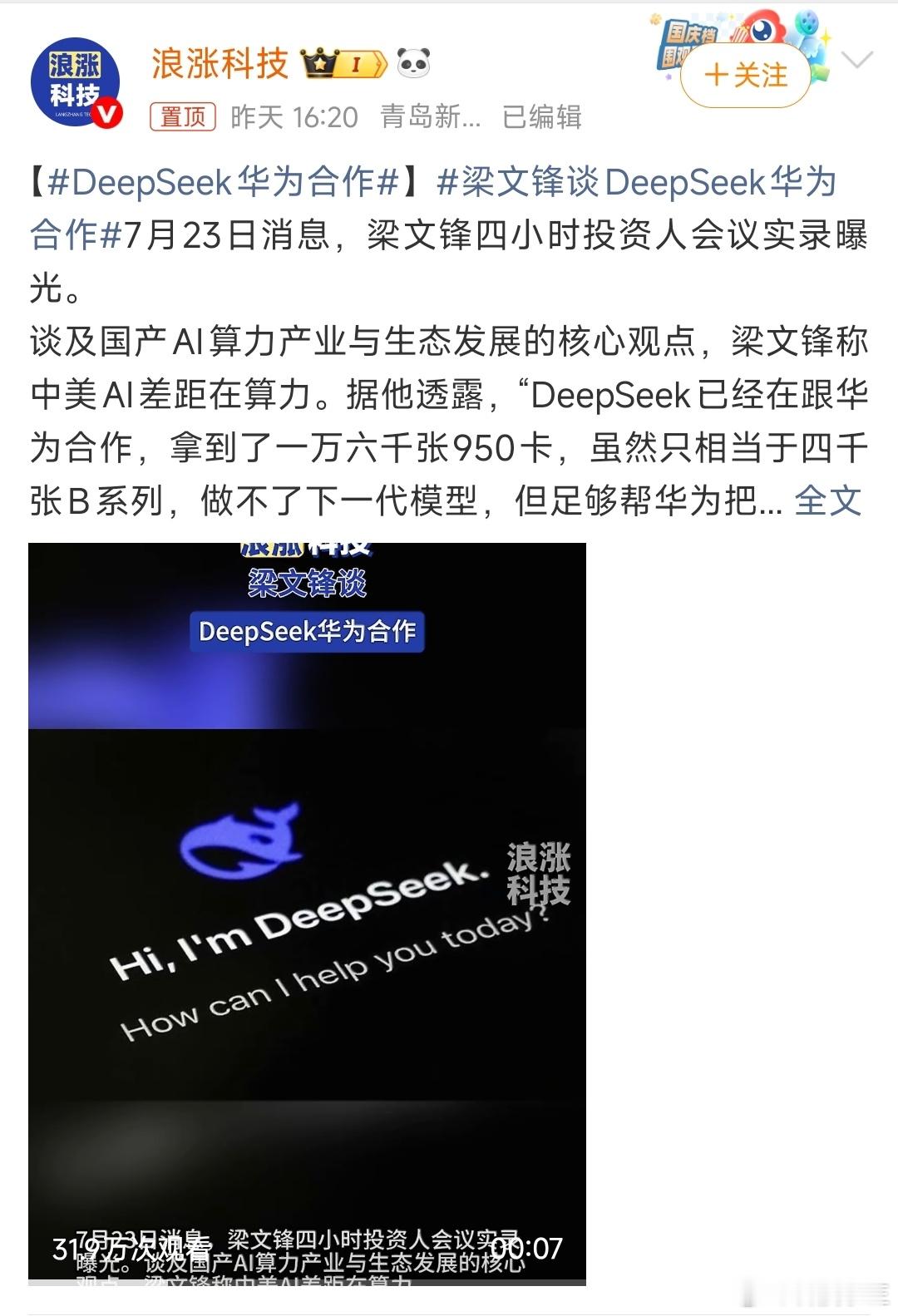
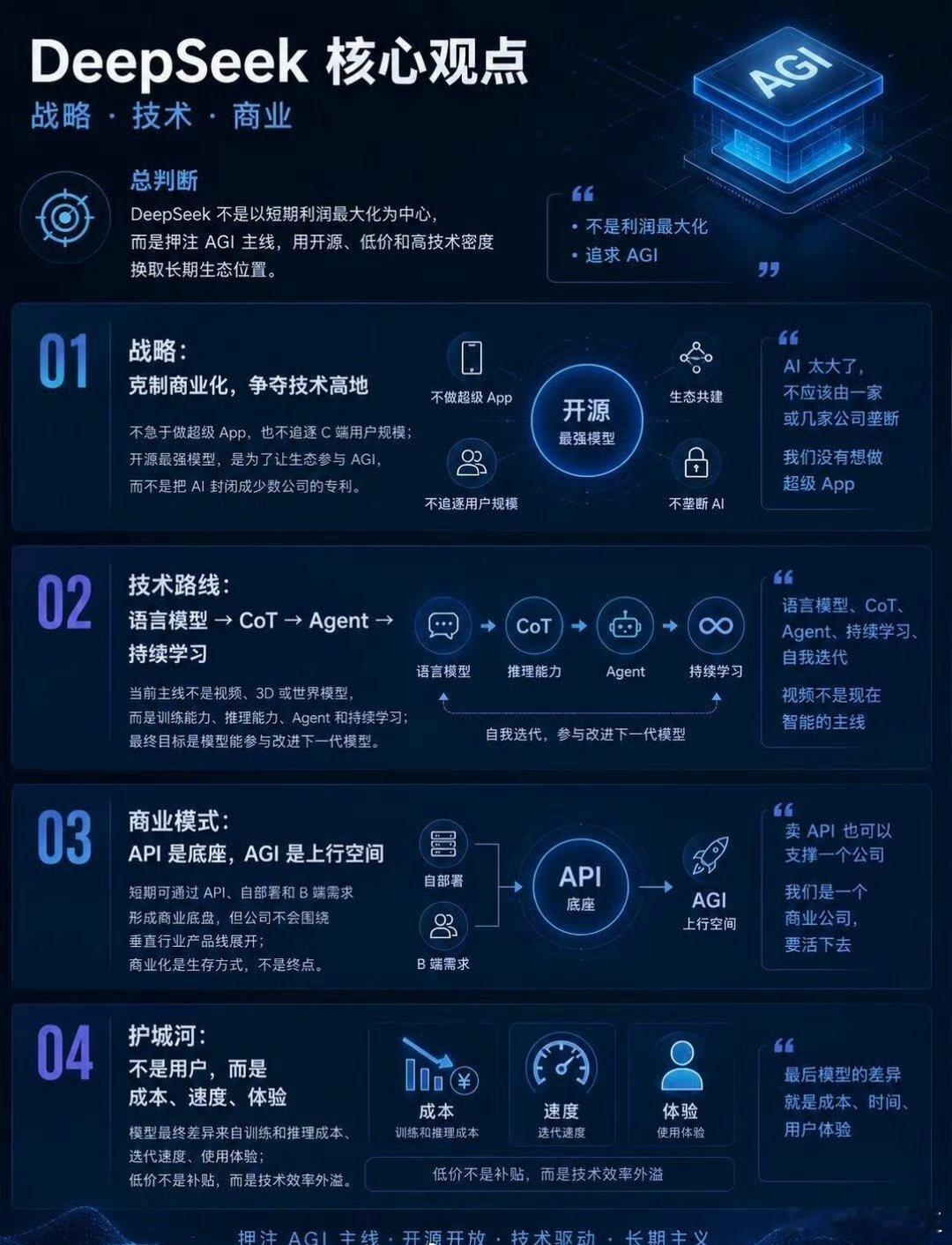
梁文锋近日的一个内部谈话流传到网上,引起网友的广泛追捧。它展现了中国新一代年轻科技精英的追梦情怀,和对待目标的执着,以及对风险的达观,老胡听了非常感动。俗话说,做事先做人,梁文锋袒露的他和团队的“愿景”,让人从中看到的可敬人格真是把美国AI巨头们甩出去好几条街。梁文锋最触动人心的几个表达包括:他的团队没有什么组织,就是愿景驱动的;公司不是靠KPI和各种考核来推动做事;DeepSeek不想成为下一个字节或者腾讯,他们执着于自己的基础研究;他们并不想利润最大化,而是只是有一定的利润就够了;开源就是让利的;他们愿意与其他公司协作,帮助任何人,甚至自己的竞争对手,因为并不会因此损失什么东西,DeepSeek本来就是开源的。这是一种境界,而且是AI时代最需要的境界。反观美国的AI两大巨头OpenAI和Anthropic,都坚持了闭源原则。OpenAI原本是公益公司,最应该搞开源大模型,却被萨姆·奥特曼在资本的支持下以“政变”方式搞成了盈利机器,现在奥特曼俨然把自己定位成了企业大亨。Anthropic一招走红后,不可一世,对科技同行严防死守,今天指控别人“蒸馏”它的技术,明天又指控别人对它使绊。说到底,他们就是想独吞AI红利,吃干抹净,而华盛顿则想利用这些大公司搞全球AI霸权,实现把全世界永远置于被压榨的地位。《外交学人》杂志周三发表了一篇文章,标题为“美国闭门造车无法赢得人工智能竞赛”,作者丹尼尔·鲍勃曾是美国议会的高级官员。他在文中特别引用了中方日前在上海举行的世界人工智能大会上的一个著名论述,“人工智能发展不应该是某个国家的独奏,而应当是全球合作的交响。”文章提到,OpenAI公司如今已不再开放,与其最初人工智能造福全人类的宗旨背道而驰。如今,OpenAI最先进的模型成了专有技术,只能通过付费界面和云服务访问。文章还评论道:“历史表明,那些最终成为全球标准的技术往往是最易于使用、修改和扩展的技术。Linux成为了互联网的基石,安卓则主导了全球智能手机市场,两者都是开源软件。它们创造的是生态系统,而非用户群体……像月之暗面、DeepSeek、智谱和阿里巴巴这样的中国公司正在越来越多地发布功能强大的开源人工智能模型,任何具备相应技术技能的人都可以下载、修改和部署这些模型。所有基于这些系统的开发者、初创公司、大学和外国政府都成为了中国不断扩展技术生态系统的一部分。与此同时,美国领先的人工智能公司却走向相反。”英伟达CEO黄仁勋周二接受美国媒体Axios采访时,抨击了美国目前涌动的对中国开源模型的恐惧。他表示,真正值得警惕的,是美国国内愈演愈烈、试图封杀这些模型的运动。黄仁勋说,“这些中国模型非常优秀,优秀的开源模型应该被使用。”梁文锋称自己和团队都是一些平凡人,并试图去做不平凡的事。但他说的所有事情都是AI领域本身的,是技术梦想。老胡作为AI圈外人士,我能更敏感地察觉到这场AI革命所触及的事物面和将带来的改变都是整个人类文明层面的,走技术开源道路是确保人类平稳站上新的历史性大台阶,并且把所有人种、所有国家一起带向未来的关键保障。AI技术如果走传统市场赢者通吃的老路,不公平等市场环境下潜藏的各种弱点,乃至恶,都将裂变式膨胀放大,那将很可能导致完全失控的,与人类基本伦理道德演进方向南辕北辙的局面。我们几乎无法预测在那样的未来里会发生什么。所以中国AI公司在一片混沌之中纷纷选择开源道路,并且取得成功,这不仅是技术和市场多元的胜利,它们的意义有可能要大得多。梁文锋、杨植麟不是单独的两个人,他们是一大批中国年轻科学家的领军者。他们共同在人类历史的重要关头不自觉地、几乎是冥冥之中推动了一种平衡,这种平衡是对霸权,对潜在伦理失控最好的抑制。它在为确保AI朝着增进人类福祉的方向前进提供一个强有力的杠杆,一种保障。如果往更远说,这样的平衡和均势是当今世界稳定与和平根基的一部分。AI时代的世界应当是真正意义上民主的,而不应是霸权主义的强势螺旋。中国的开源公司们在向世界提供更多技术选择的同时,也让国家间保持相互尊重、平等互利的关系有了一个强有力的抓手,也是一只锚。我相信,梁文锋、杨植麟他们根本就没想过老胡说的这些事,他们只是按照中国和世界文明代代相传的道德直觉和价值逻辑做事。他们在很聪明的同时,也做到了很勤奋。他们的成功在这个时代是呼之欲出的,他们不负众望地站到了在群山之间跋涉的一个临时高峰上。AI时代刚刚开个头,未来是令人兴奋不已的盲盒。然而现在就能看到的是,美国什么都搞封锁,什么都搞闭源,他们一定会碰钉子,很多政策和愿景的调整,在美国AI界势必要发生。老胡相信,未来肯定不会是美国和中国一家完胜,另一家满盘皆输的零和局面。中美AI技术和模式的相互渗透,老胡这个文科生都能看得到。AI决不可能只是算力的比拼,它注定是在回答人类一个又一个命题中,施展魔力的超级舞台。老胡很高兴,中国的年轻科学家们从一开始就找对了大方向,尽管中间会有各种弯道和岔路口,但他们心中有一个永恒的人文罗盘,它的作用就是确保永不迷航。