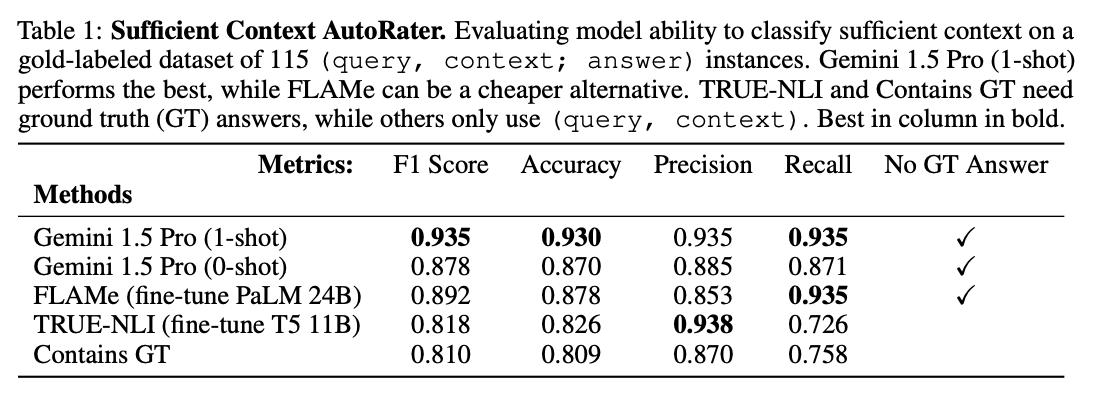
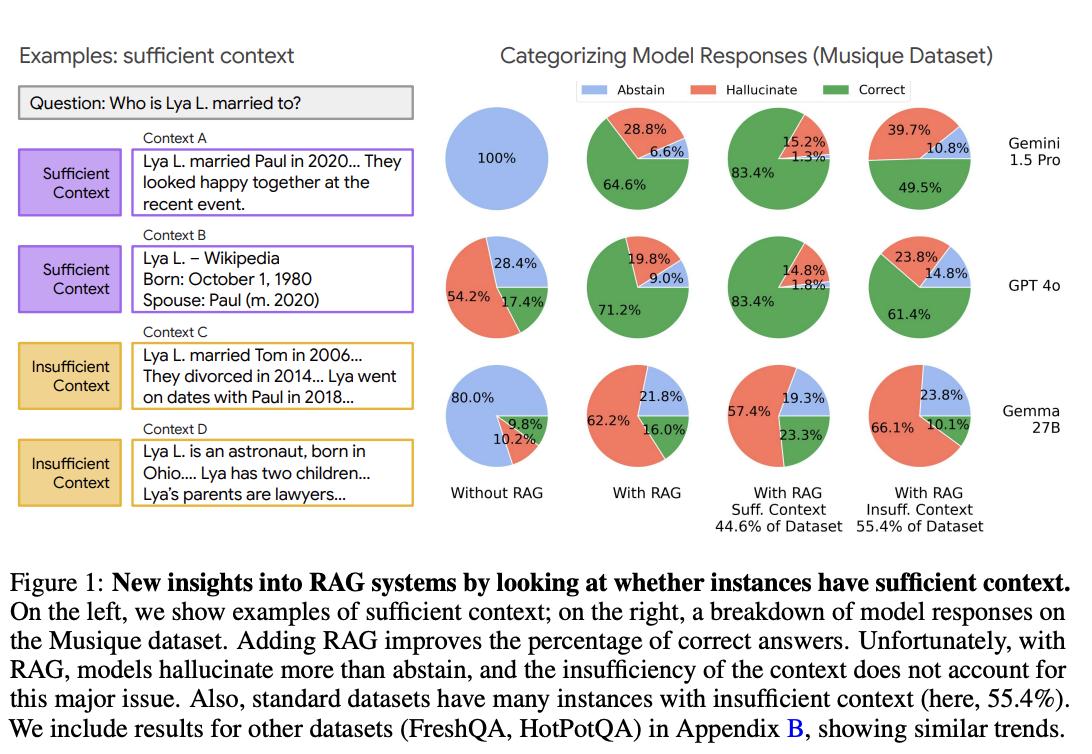
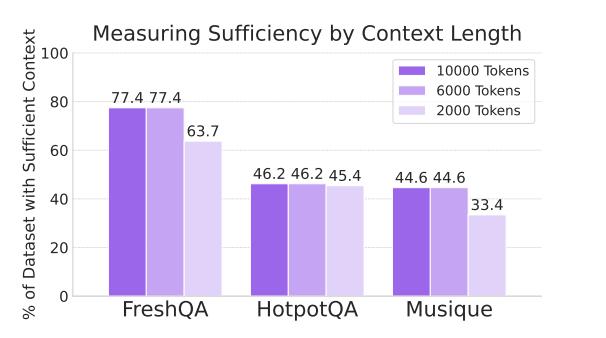
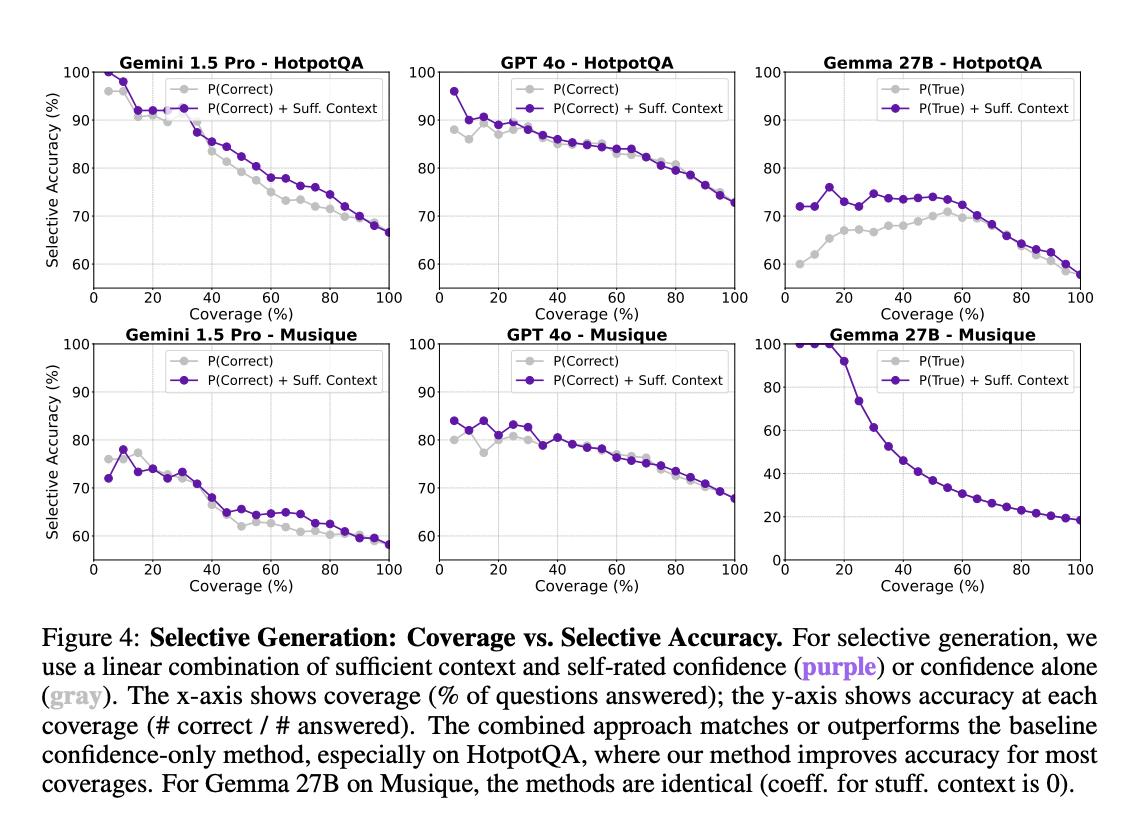
大模型真能判断“信息够用”了吗? 尽管针对RAG(检索增强生成)系统已有大量研究,但始终存在一个关键谜题:当大模型回答出错时,究竟是因为没用好给它的信息,还是因为信息本身就不够回答问题? 为了搞清楚这个问题,来自谷歌的研究团队提出了“充分上下文”的概念,来评估提供给大模型的信息是否足够回答问题。 他们开发了一个基于Gemini 1.5 Pro的自动标注器,用于标记实例是否具有充足上下文,准确率高达93%,无需真实答案即可进行大规模评估。【图1】 研究团队在对主流数据集(如HotPotQA、Musique)进行分析时发现,即使是人工筛选过或在“理想检索”的条件下,仍有甚至超过一半的问题缺乏充足上下文。【图2】 研究发现:【图3】 基线性能较高的大型模型(如Gemini 1.5 Pro、GPT-4o和Claude 3.5)在上下文充足时表现出色,但上下文不足时宁可编错答案也不愿说“不知道”。 基线性能较低的小型模型(如Mistral 3和Gemma 2)即便上下文充足,也频繁放弃回答或胡编乱造。 为了改进模型的表现,研究团队提出了一种“选择性生成”方法。 这种方法会结合模型自身的“自信程度”以及上下文充分性来做决定,如果模型不确定,或者信息不够,它就会选择不回答。 这种方法相当有效,使用选择性生成方法后,模型在回答问题时的正确率提高了2-10%。【图4】 论文地址: 代码仓库: