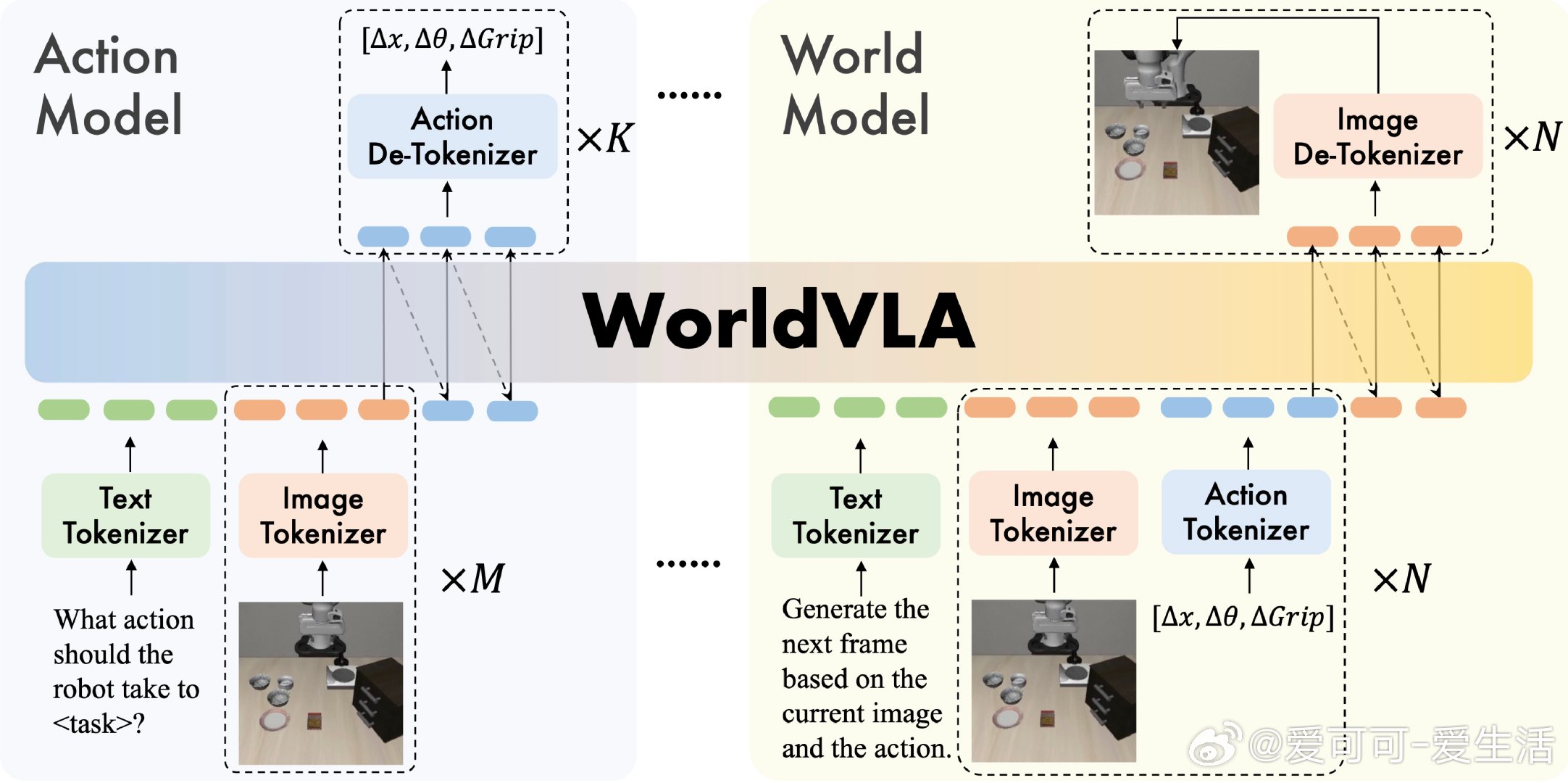
【[80星]WorldVLA:一个自回归动作世界模型,将动作和图像理解与生成统一在一个框架内。亮点:1. 在LIBERO基准测试中,动作模型成功率最高达96.2%;2. 支持多种任务和图像分辨率(256×256和512×512);3. 提供完整的训练和评估代码】
'WorldVLA: Towards Autoregressive Action World Model'
GitHub: github.com/alibaba-damo-academy/WorldVLA
动作模型 视觉语言动作 自回归模型 人工智能 ai兴趣创作计划