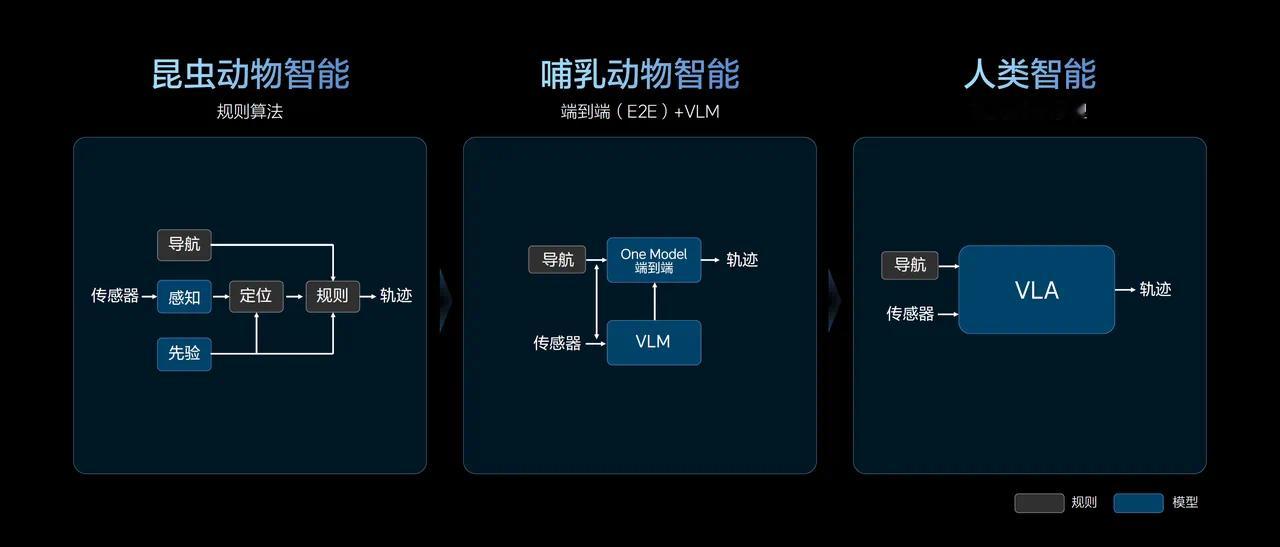
到了 VLA 阶段的架构图看着更简单了?其实背后也有不少技术点,理想分享了 VLA 司机大模型所包含的模块细节:
首先是空间编码器,车子上虽然装了很多摄像头、雷达,能看到各种信息,
但“大模型”本身不认识什么叫车道线、红绿灯、障碍物。
空间编码器的作用,就是把这些信息整理成机器能理解的“场景语言”,
让模型知道:这是一条什么样的路,有哪些可行驶区域、有哪些禁止进入的地方,谁是行人、谁是车,环境几何结构是什么样的。
这个环节相当于“翻译现场”,一张系统自己看得懂的地图,这一步如果做不好,后面再聪明的模型也只能瞎猜。
————
接着是Diffusion轨迹预测。我们常说辅助驾驶系统要「看懂别人想干嘛」,
但很多场景下别人的行为是模糊的,比如对向车辆会不会突然左转、旁边电动车会不会横穿马路。
这时,Diffusion就可以生成多个合理的轨迹可能性,并通过反复采样优化,选出最可能发生的结果。
它的好处在于不死板、不简单猜平均值,而是像老司机那样提前“预判风险”。
————
第三是MoE混合专家结构。它解决的是「复杂任务不能一个模型全包」的问题。
理想的做法是,把大模型拆成很多个「专家」,有的专门判断红绿灯,有的处理插队变道,有的负责并线跟车。
每次行车中只激活部分专家,就像队伍里只叫懂行的上场,节省算力又能保证效率。
这种结构比传统大模型更高效,也更容易扩展新技能,对芯片算力释放和功耗优化都有所帮助。
————
第四是Sparse Attention(稀疏注意力),大模型处理的信息量非常大,但车载芯片算力是有限的,所以必须学会“只关注重点”。
Sparse Attention的作用是让模型像人一样只看关键区域,比如准备并线时,就集中注意后方侧后方的区域;在路口转弯时,优先处理左侧来车或行人位置。
这种注意力机制既加快处理速度,又提升判断精度,是落地不可或缺的关键优化。
————
最后 RLHF就是基于人类反馈的强化学习,辅助驾驶并不只是完成动作,而是要有人的路感。
比如红绿灯刚变绿不一定马上起步,骑电动车的人摇摇晃晃可能不稳定,夜间远光灯可能误导感知系统……这些不是写死的规则,而是靠大量真实人类反馈训练出来的“经验值”。
RLHF技术让模型逐渐掌握这些“老司机的判断”,表现出更自然、更安全的驾驶风格。
————
当这些技术组合起来,就形成了一个既理解场景、又会预判、还能学经验的大模型驾驶系统,
并且在这之上还引入了自然语言交互、多模态指令这些AI能力,让用户更方便、更有感知的使用,
最终形成一套「听得懂话、看得懂路、开得像人」的自动辅助驾驶系统,或者说是 Agent 助手。
理想汽车[超话]汽场全开新能源大牛说