昨天看完了理想发布的 MindVLA-o1 ,太专业了以至于理解的不是特别容易,到底是什么?理想发布下一代自动驾驶基础模型 一个最简单的例子解释:以前的自动驾驶,其实更像一个“反应型司机”:看到红灯 → 刹车看到前车减速 → 跟着减速导航让右转 → 执行右转
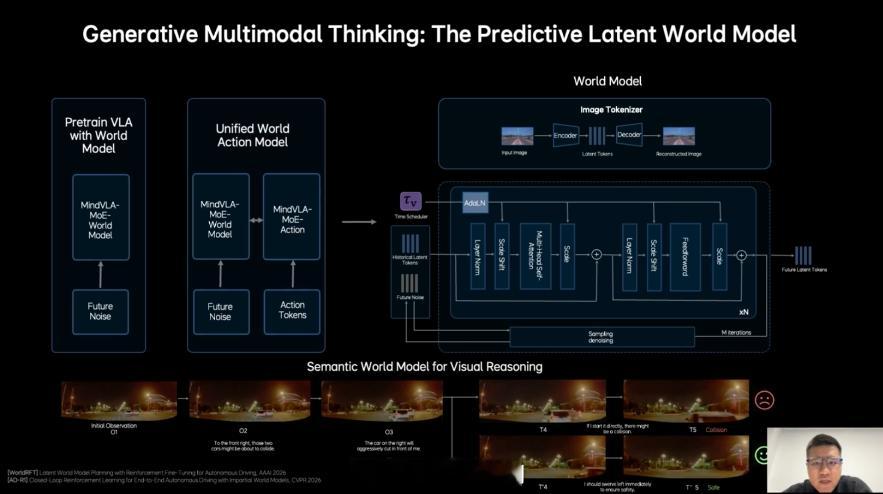
本质是 “看见什么 → 做什么”。但真正的人类老司机不是这样开车的。比如你经过一个路口时,大脑其实在同时想很多事:前面公交可能要进站左边电动车可能会抢道右边有人可能要过马路于是你会提前减速、提前让行、提前规划路线。
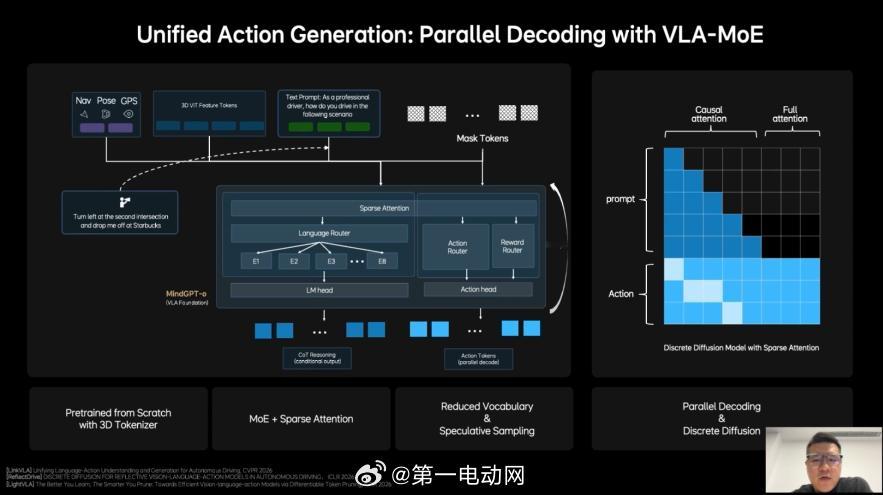
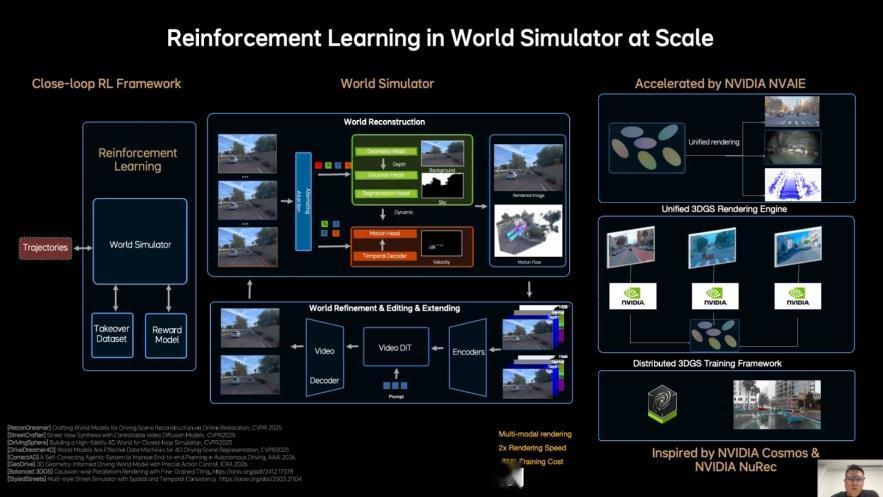
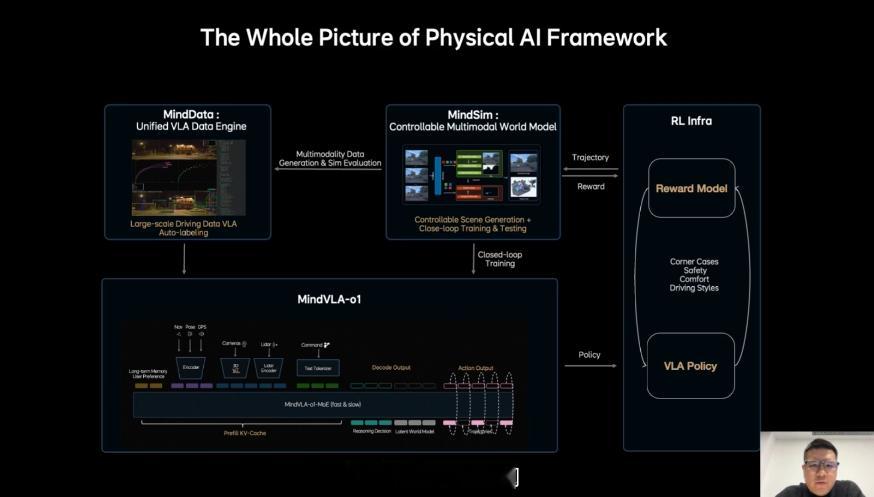
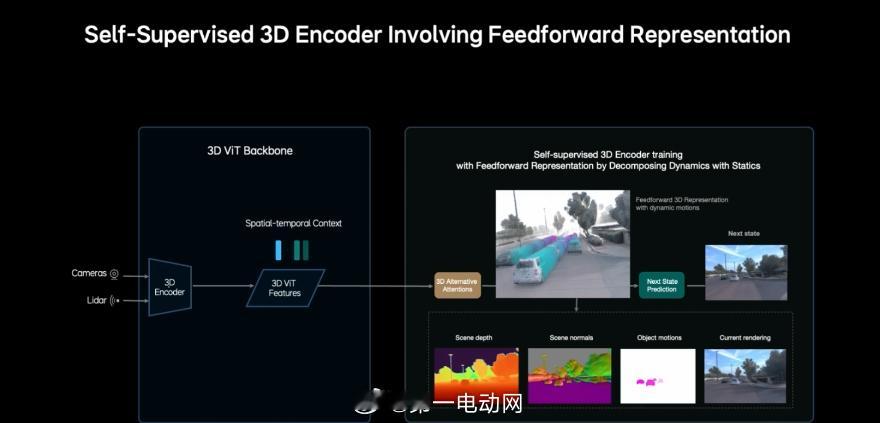
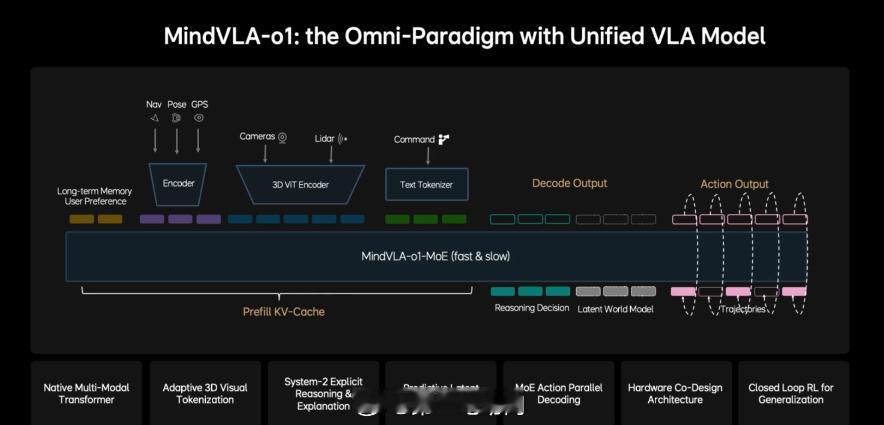
理想这次做的 MindVLA-o1,核心其实就是一件事:让车像老司机一样,会“提前想几步”。它把三件事放进一个统一的大模型里:
看:理解3D道路环境想:在脑子里模拟未来几秒的交通变化做:生成驾驶轨迹并执行
也就是所谓的 VLA(视觉-语言-动作)模型。
所以理想内部有一句很有意思的话:车其实是最大的机器人。自动驾驶只是第一步。未来同一套AI模型理论上可以:开车控制机器人控制各种现实世界设备
以前自动驾驶像“程序在开车”,现在开始变成“AI司机在开车”。
这可能才是自动驾驶真正的大模型方向。自动驾驶