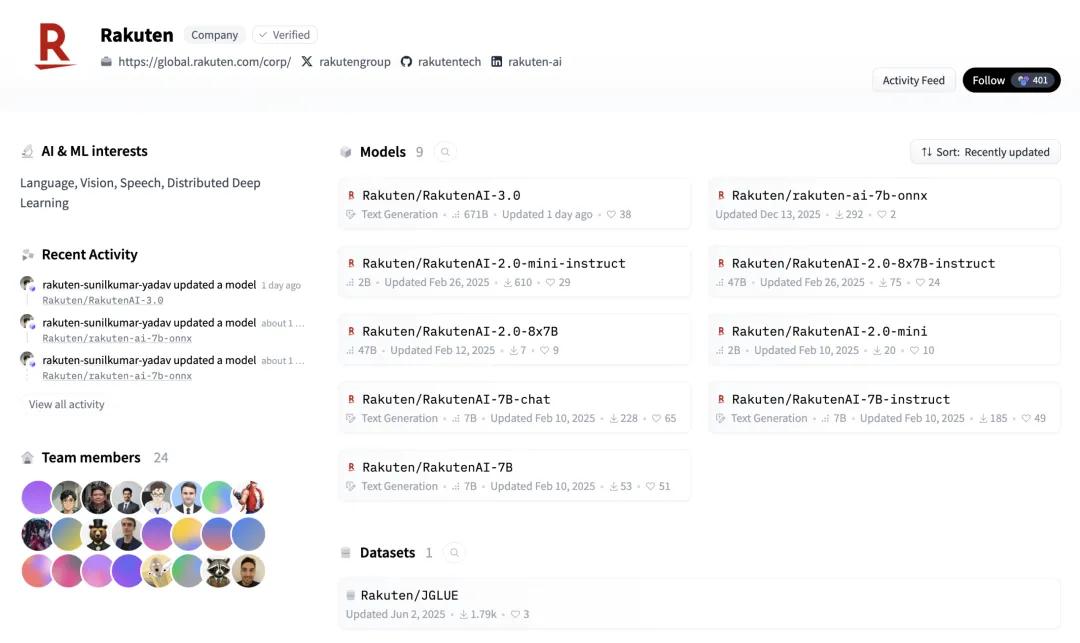
2026 年 3 月 17 日,日本乐天集团发布大模型 Rakuten AI 3.0,并将其定义为在日本经济产业省与 NEDO 推动的 GENIAC 项目框架下开发的“日本国内最大规模高性能 AI 模型”。

乐天称,该模型约为 7000 亿参数的 MoE 架构,面向日语优化,可用于写作、代码生成、文档分析等场景,并以 Apache 2.0 许可在 Hugging Face 上免费开放。
不过,模型上线后不久,技术社区很快发现 Rakuten AI 3.0 的底层配置与 DeepSeek - V3 高度一致。
乐天在 Hugging Face 发布的 config.json 文件中,architectures 一栏写的是 DeepseekV3ForCausalLM,model_type 则直接标注为 deepseek_v3;而 DeepSeek-V3 官方仓库的对应字段也是同样写法。

双方公开信息中的关键规格也几乎完全重合。
Rakuten AI 3.0 在模型页中写明,总参数量 671B、每个 token 激活参数 37B;DeepSeek-V3 官方仓库对外公开的核心规格同样是 671B 总参数、37B 激活参数。

这意味着,Rakuten AI 3.0 并非外界通常理解的“从零打造的全新底座模型”,而更像是在 DeepSeek-V3 基础上,进一步做了日语方向的训练和优化。
争议也因此迅速集中到信息披露层面。
乐天在新闻稿中强调,Rakuten AI 3.0 “充分利用开源社区最佳成果”,并突出其在日本语基准测试中的表现,但并未在发布正文中直接点名 DeepSeek。
对于一家拿到日本政府 GENIAC 项目支持、同时以“日本最大规模”进行传播的企业来说,这种表述被不少观察者认为过于模糊,容易让外界误以为其底座能力主要来自内部原创研发。 
另一个引发讨论的点是开源许可处理。
DeepSeek-V3 的公开仓库显示,其代码文件采用 MIT License,其中明确要求保留版权声明和许可声明。

乐天的 Hugging Face 仓库首页则显示项目采用 Apache-2.0,同时提交记录显示,该仓库在最初上传后,又新增了 NOTICE 文件,并出现了 “Add the permission notice” 的提交说明。这一变化进一步加剧了外界对其署名和许可合规处理是否充分的质疑。

从开源规则看,基于开源模型进行再训练、微调和本地化并不罕见,本身也不必然构成问题。
真正引发争议的,是乐天在宣传口径上更强调“日本最大、最强”,却没有在最醒目的位置清楚交代底座来源;而在许可文件补充出现在模型上线之后的背景下,这场发布会也从一场日本本土大模型成果展示,迅速演变成一场围绕开源透明度与技术归属的舆论风波。
整体来看,Rakuten AI 3.0 更准确的定位,或许不是“日本从零做出的 7000 亿参数原创底座”,而是一个建立在 DeepSeek-V3 开源技术之上、面向日语做深度优化的超大模型版本。
据《日经中文网》基于其“AI 模型评分”报道,在日本企业开发的前 10 个模型中,有 6 个以 DeepSeek 或 Qwen 为底座进行了二次开发。