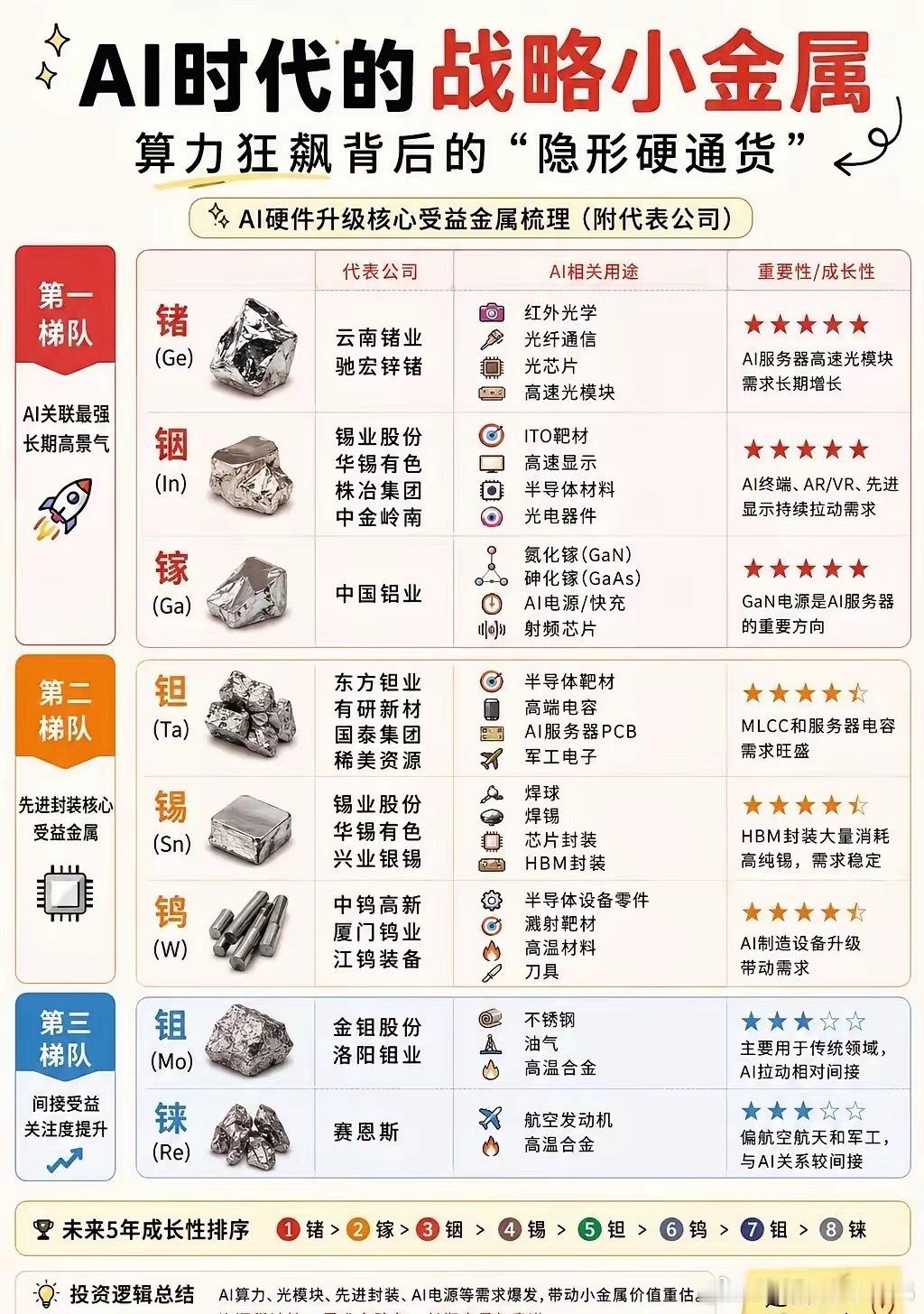
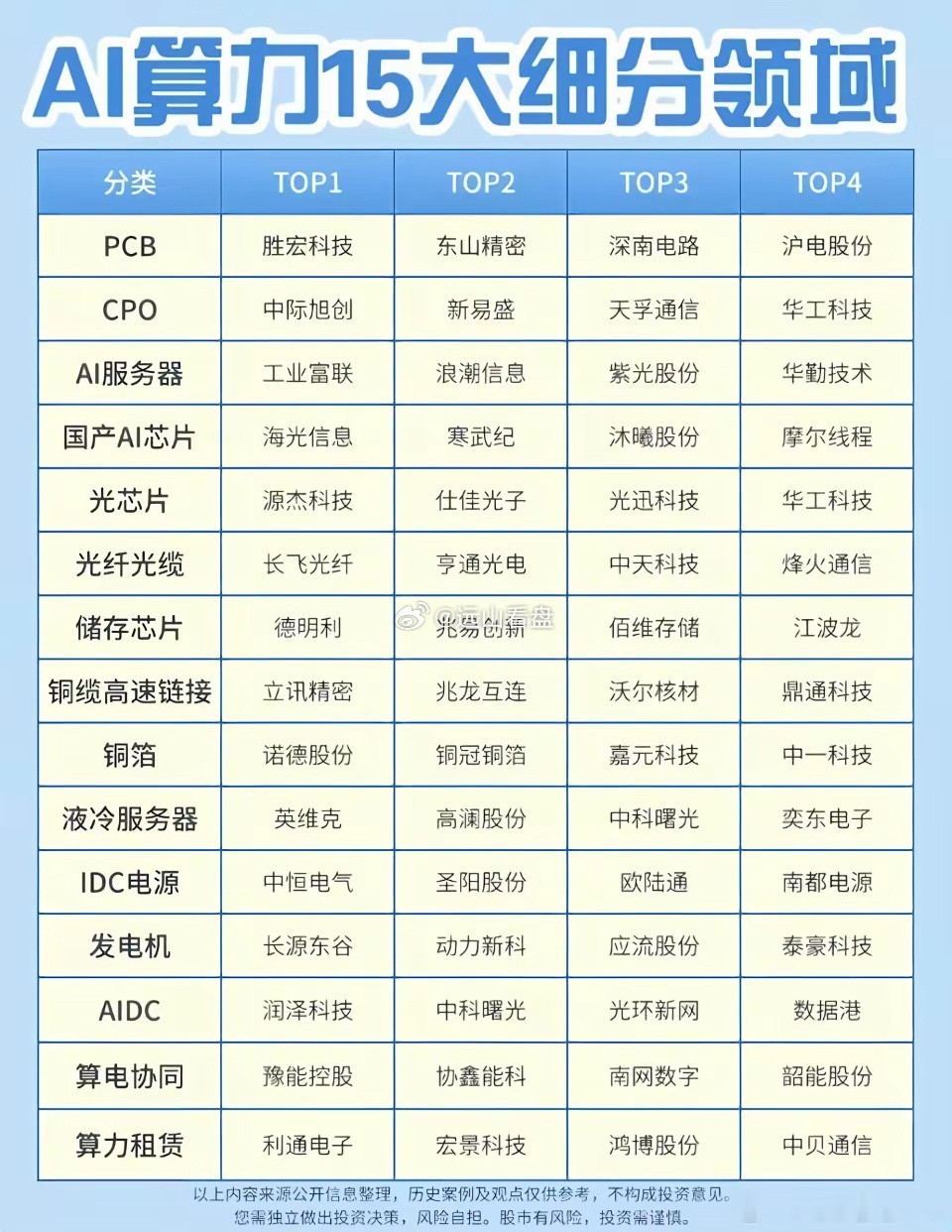
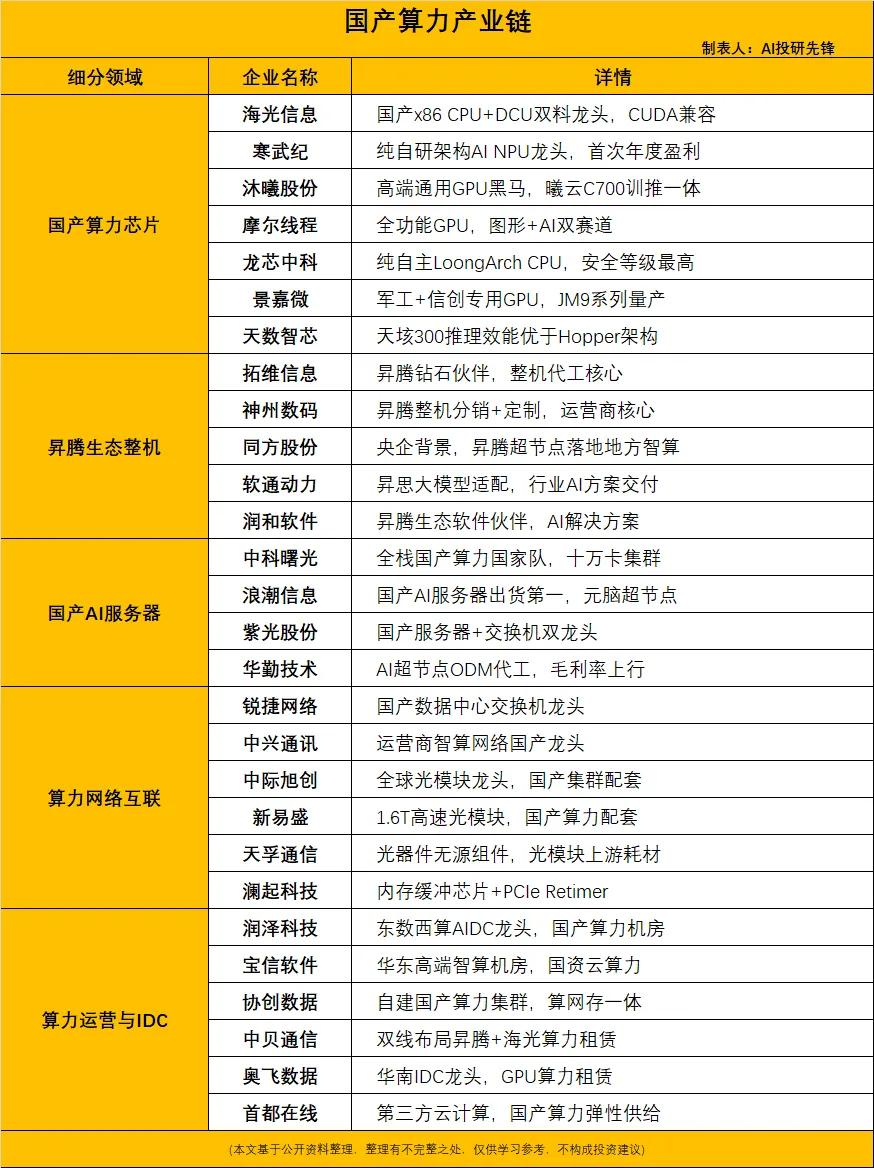
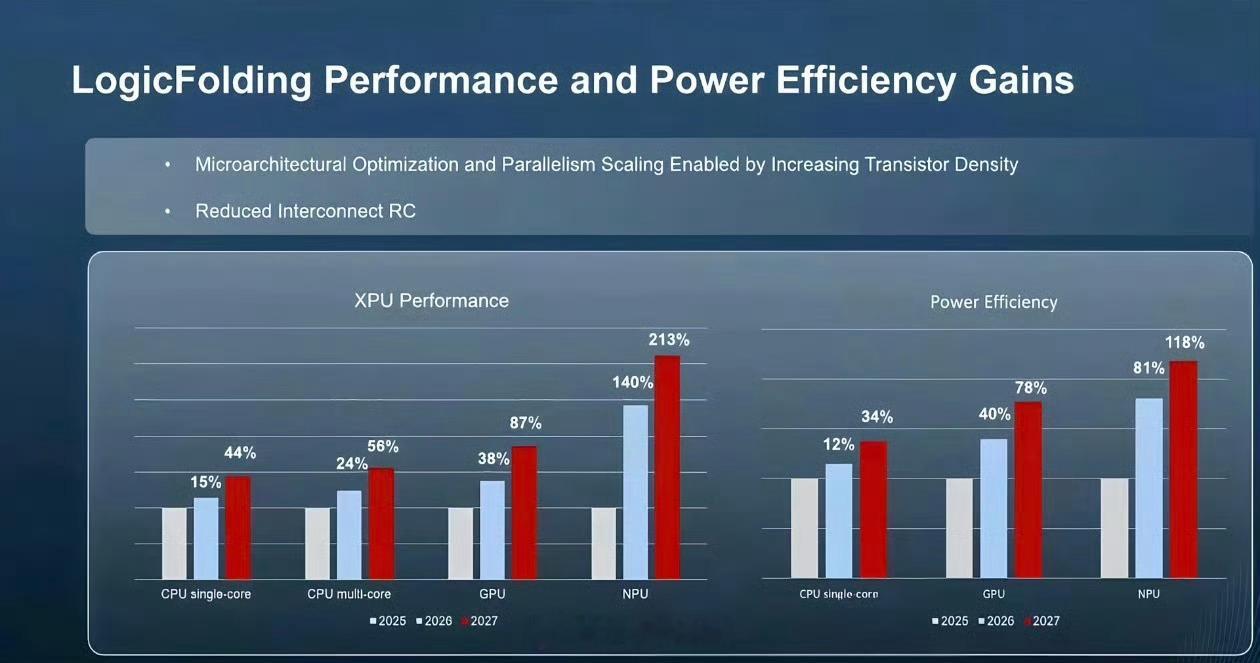
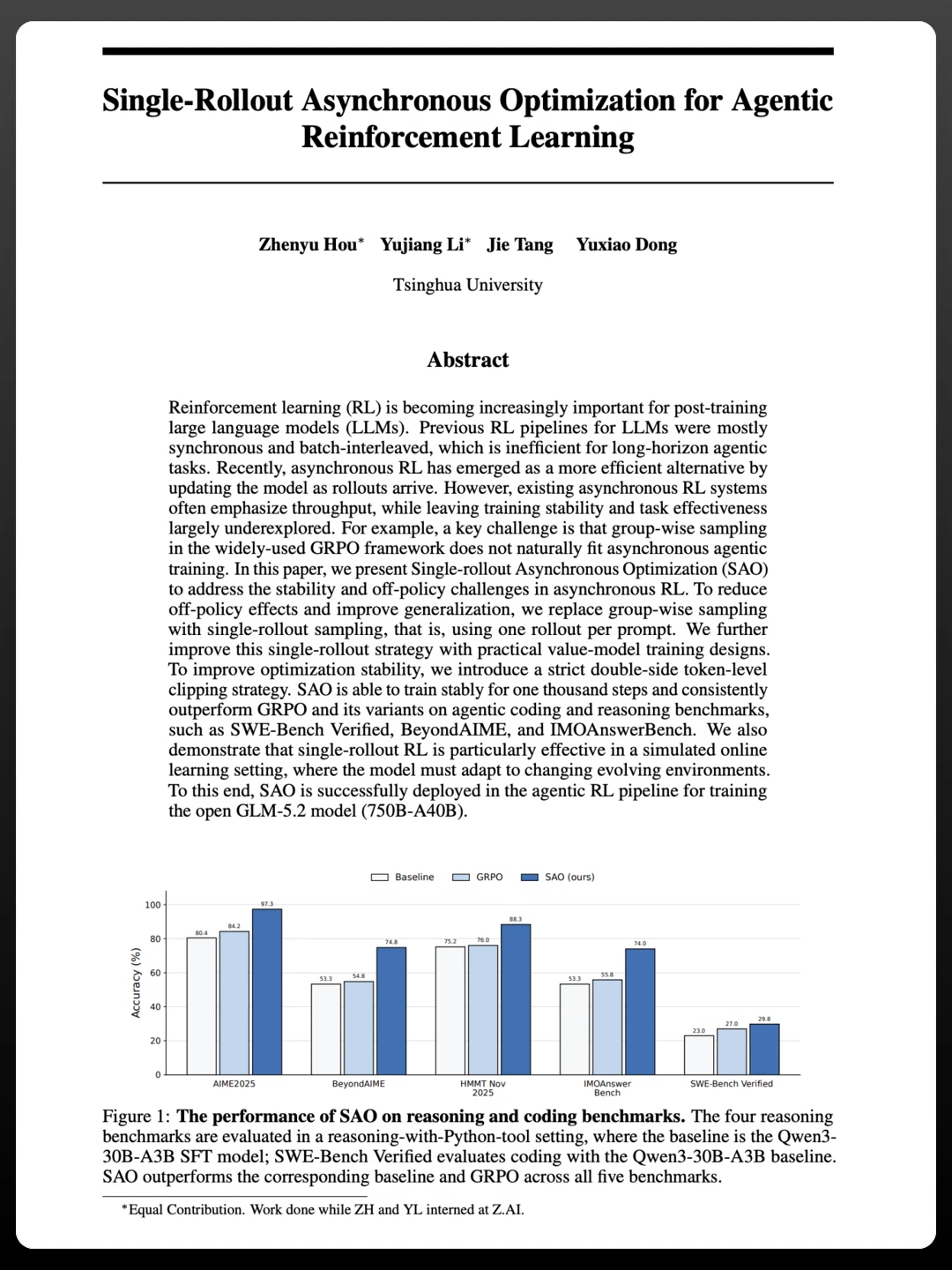
标签: GPU


互联网技术AI泡沫的出清不会是"全行业雪崩",而是一次极其精准的优胜劣汰——谁
互联网技术AI泡沫的出清不会是"全行业雪崩",而是一次极其精准的优胜劣汰——谁靠叙事活着,谁靠现金流活着,潮水退去时一目了然。综合高盛、BIS、摩根士丹利、Forrester等机构的判断,以及新华网披露的全球AI投入1.4万亿美元vs营收6130亿美元的残酷断层,以下五类行业将面临最大挑战,且冲击会沿产业链逐级传导。一、最惨重:高杠杆算力基础设施与数据中心租赁这是泡沫破裂的"震中"。高盛在7月中旬的研报中明确指出,"算力扩张时代"正逐步走向终结,整个科技板块的估值定价体系即将迎来重构——资本开支效率、资产利用率、应用落地速度将取代"硬件产能规模"成为新的定价因子。挑战来自三个方向的夹击:-债务期限错配:科技巨头通过发债为AI基建"输血",彭博数据显示自2025年初以来美国已发行超过3700亿美元的AI债券融资产品。但数据中心、算力设备技术迭代快、折旧周期短,与中长期债务明显错配-资产闲置风险:一旦需求不及预期,万亿级"暗算力"将出现,运营商债务风险陡升。甲骨文就是前车之鉴——其自由现金流已暴跌至-59亿美元-抵押物贬值:部分算力租赁公司以GPU为抵押融资,但GPU迭代极快,新一代芯片上市后旧型号租金下跌,存量GPU的二手价值和抵押价值同步缩水,金融机构可能要求补充抵押物或提前还款摩根大通数据显示,当前美国四大云厂商2026年AI资本开支将高达7250亿美元,但三季度合计自由现金流预期将砸至约40亿美元——创下近十年来绝对低点。这种"表内失血+表外6620亿美元租赁承诺"的结构,一旦算力项目交付起租,账面真实债务将面临结构性翻倍。中国的具体风险点:依赖进口GPU的中小算力租赁商、无差异化优势的智算中心。上海市经信中心的报告明确指出,上海大量应用层且未盈利的AI企业面临资金链紧张,A股AI成分股中仅四成实现利润增长、三成陷入亏损。二、最直接:半导体存储与光通信硬件链这是已经能看到拐点的行业。存储芯片的拐点信号已经出现。摩根士丹利7月21日的报告警告:AI驱动的存储超级周期正接近拐点,内存合同价格预计将于2026年四季度见顶。数据显示净盈利上调率已从92%的峰值回落至77%,SK海力士市净率已从高点回落至2.5倍,三星降至1.7倍。更具杀伤力的是供需逆转的预期:-台积电宣布大幅上调年度资本支出,未来三年大规模扩产先进制程-全球存储大厂持续扩产,机构预判2027年全球芯片、存储或将迎来新一轮产能过剩周期-韩国作为全球AI产业链最脆弱、杠杆最高的位置,其HBM预期下行将引发全球AI硬件需求重估光模块、PCB、液冷设备同样面临挑战。800G/1.6T需求骤减的风险已经显现,上半年这些环节因"瓶颈叙事"获得极高估值溢价,但一旦算力建设放缓,高速光模块订单下滑、估值腰斩的压力将集中释放。大摩的判断值得重视:本轮存储周期将走向"拉长"而非"直接崩溃"——这意味着不是断崖式暴跌,而是长达12-18个月的漫长估值消化期,对相关企业来说是"温水煮青蛙"式的挑战。三、最残酷:未盈利大模型与AI应用初创公司这是死亡率最高的群体。MIT调查显示95%的企业布局AI后未能收获可量化的商业回报;高德纳预警2027年末将有超四成AI智能体项目被迫终止。商业回报的缺失,让这一层的所有玩家都坐在火药桶上:头部大模型公司:OpenAI、Anthropic两家估值合计超1.8万亿美元,年化收入合计仅700亿美元,20-25倍市销率明显高于微软、谷歌等巨头(10倍上下)。更关键的是现金流——德意志银行报告显示OpenAI最早要到2030年才有望实现现金流转正,Anthropic虽有望在2026年二季度首次单季度盈利但盈利不足6亿美元。中小模型与套壳公司:启明创投预判,未来12-24个月顶尖模型将内化任务规划、工具调用、多Agent协同等能力,直接"降维打击"靠套壳和编排存活的中间层公司。国内370多家具身智能企业中,没有实际落地产品、仅靠概念融资的,将面临生存危机。纯概念ToC应用:智谱清言、Minimax星野等产品月活不足千万,用户留存率持续下滑;Minimax海外流量占比过高,国内C端业务尚未找到可持续的商业模式。一级市场的"灭绝潮":美元基金年度融资额从2021年的5329亿元萎缩至2025年的827亿元,跌幅逾84%。上海市经信中心预警:上海AI应用层占比超85%,大量腰部以下企业面临融资困难,或被整合淘汰。四、最隐蔽:水平SaaS与传统企业软件的"存在性危机"这是被市场严重低估的挑战——不是业绩下滑,而是商业模式根基动摇。Forrester在2026年2月的一份重磅报告中指出,SaaS公司估值在七天之内蒸发超过1万亿美元,触发因素是市场意识到AIAgent可能从根本上改变工作完成的方式。投资者逃离SaaS有四个核心担忧:1.SaaS公司不会成为AIAgent的首选提供者2.传统的"按席位收费"模式将过时,导致收入下降3."氛围编程"(vibecoding)让初创公司能复制复杂SaaS平台的功能,侵蚀护城河4.SaaS产品本身过于复杂,用户疲于管理数百个互不相通的应用结构性冲突在于:SaaS企业长期采用"按席位收费"模式,本质上与就业规模高度挂钩;但AI提升生产力的逻辑,恰恰意味着企业可能减少员工数量——如果企业用大模型工具自建自动化流程,部分中后台软件需求将被削弱。Forrester的预测很明确:低切换成本、弱嵌入式企业工作流的水平点解决方案SaaS厂商将被挑战;那些无法提供即时、可量化ROI的厂商将失去资金和客户;只有垂直化、领域特定的SaaS厂商(如医疗、制造业)或控制独特专有数据的厂商才能存活。这意味着:企业办公AI、AI营销、AI教育等"水平赛道"挑战最大;而工业AI、医疗AI、金融AI等"垂直刚需"赛道韧性强,解决真实痛点、有现金流的企业将在估值回调后存活,龙头集中度反而提升。五、最深远:亚洲服务外包与AI驱动的区域产业重构这是被讨论最少、但影响面最大的挑战。路透社援引高盛估算,美国约2.5%的就业岗位面临AI风险,主要集中在客户服务、计算机支持和业务运营等领域——而这些恰恰是跨国公司多年来外包给亚洲的工作。具体冲击:-印度IT服务:塔塔咨询服务、Infosys、Wipro等过去一年表现严重落后-菲律宾业务流程外包(BPO):该国约一半的服务出口包括BPO、呼叫中心和IT服务,外国投资者今年已从菲律宾撤资8.4亿美元,主要股指暴跌超过10%-韩国半导体:作为全球AI产业链最脆弱、杠杆最高的位置,其HBM预期下行将导致全球AI硬件需求重估这是AI泡沫出清中唯一的"实体经济就业冲击"——前面的挑战主要集中在资本市场和科技行业内部,而这一层的挑战将直接传导至新兴市场国家的GDP和就业。中国的差异化处境:双轨周期下的"危"与"机"中国在这一轮全球共振中呈现出独特的"双轨"特征:承压的一面:-外销型、绑定英伟达的AI企业:将遭遇海外客户缩减资本开支、美国芯片管制持续收紧、全球科技估值回调三重打击-A股1060家AI成分股中,仅四成利润增长、三成亏损,大量腰部以下企业面临融资困难-依赖进口GPU的中小算力租赁商、无落地通用AI初创企业韧性的一面:-英伟达在华份额从95%跌至55%,国产AI芯片国产化率达41%,形成了隔离海外泡沫冲击的独立周期-字节、阿里等自带流量的平台型公司,将受益于算力降价带来的成本收缩-工业AI、政务垂直AI、华为昇腾/寒武纪等国产算力芯片,具备穿越周期的属性BCAResearch复盘四次历史资本支出热潮后发现,当前AI领域已显现五大崩塌规律的早期迹象。但这并不意味着灾难——正如高盛报告所指出的,下一阶段的行业赢家未必是基建规模最大的企业,而是那些拥有稳定电力保障、算力利用率高、商业化路径清晰的算力运营服务商。对行业参与者的核心启示:-硬件厂商比拼的不是扩产速度,而是高端产能实力与真实业绩兑现能力-软件厂商必须从"工具"转型为"智能体",否则将面临商业模式的生死考验-创业公司必须找到能付钱的场景、深度解决具体问题,而非停留在demo阶段-投资者应建立算力利用率、单位Token成本、行业ROI、绿电比例、数据合规这五把硬约束尺子泡沫出清的本质,是市场从"建设思维"转向"运营思维"、从"硬件产能规模"转向"商业化落地收入"的估值体系重构。在这个过程中,挑战最大的行业恰恰是过去两年受益于AI叙事最深的行业;而真正具备技术壁垒、场景闭环和现金流能力的企业,将在洗牌中诞生为下一阶段的龙头。历史不会简单重复,但总是押着相似的韵脚——2000年互联网泡沫破裂后,存活下来的亚马逊、谷歌最终定义了云时代;这一轮AI泡沫出清后,活下来的企业也将定义下一个十年的智能时代。区别只在于:谁能在潮水退去前,找到自己的泳裤。













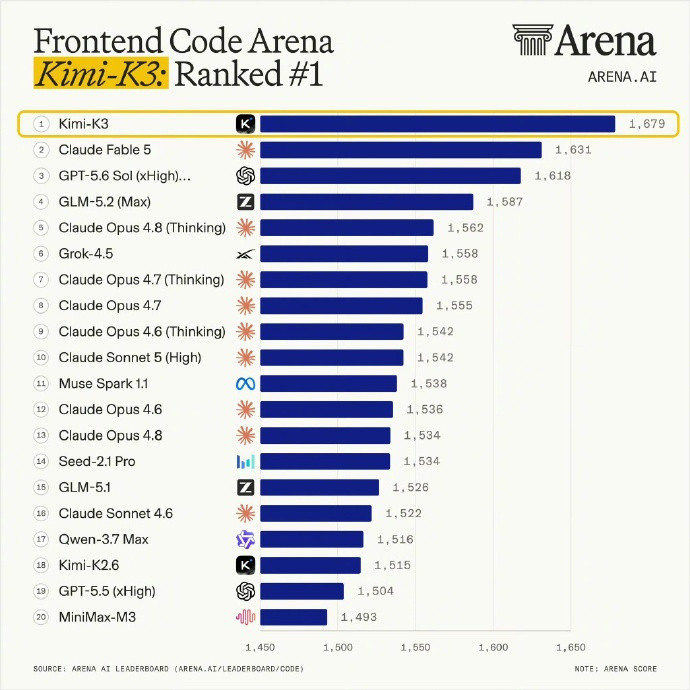


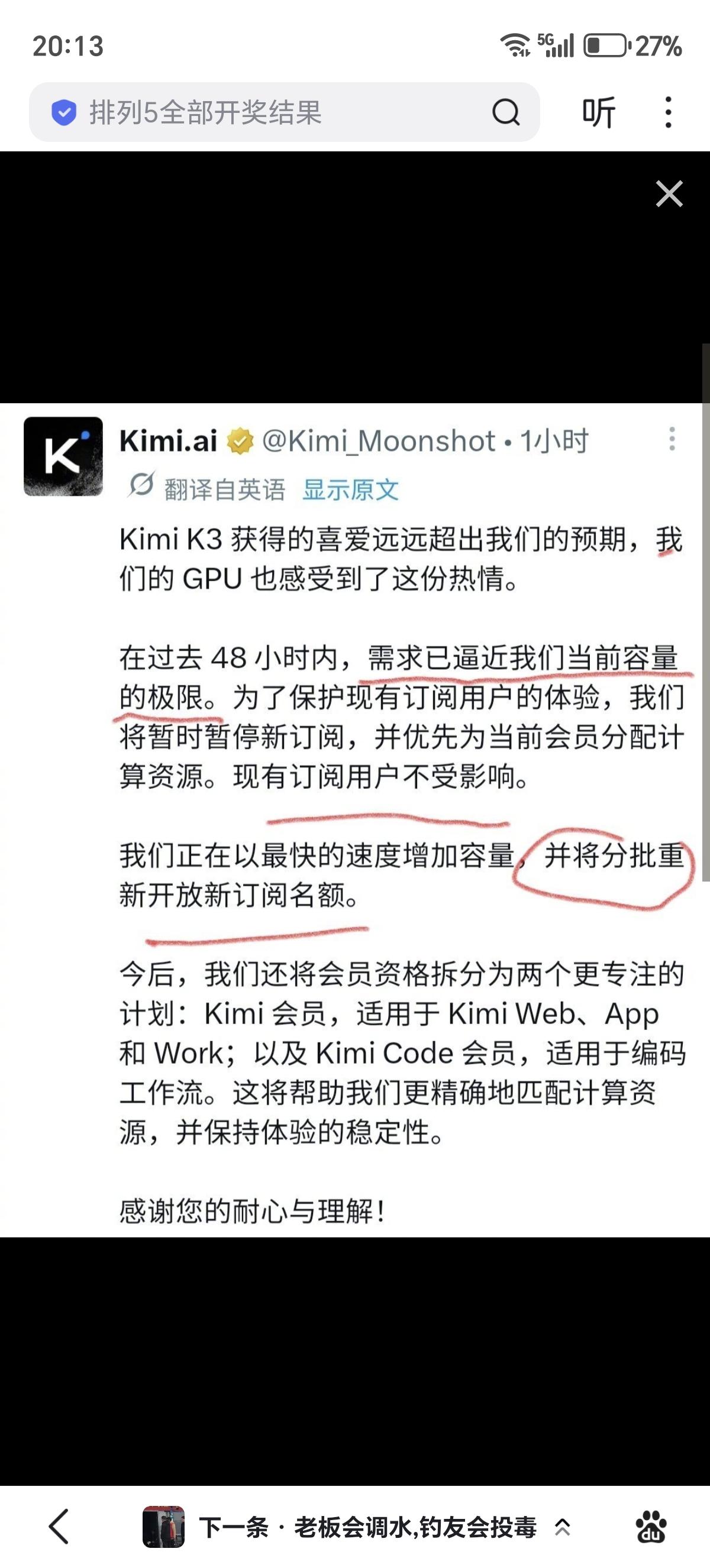
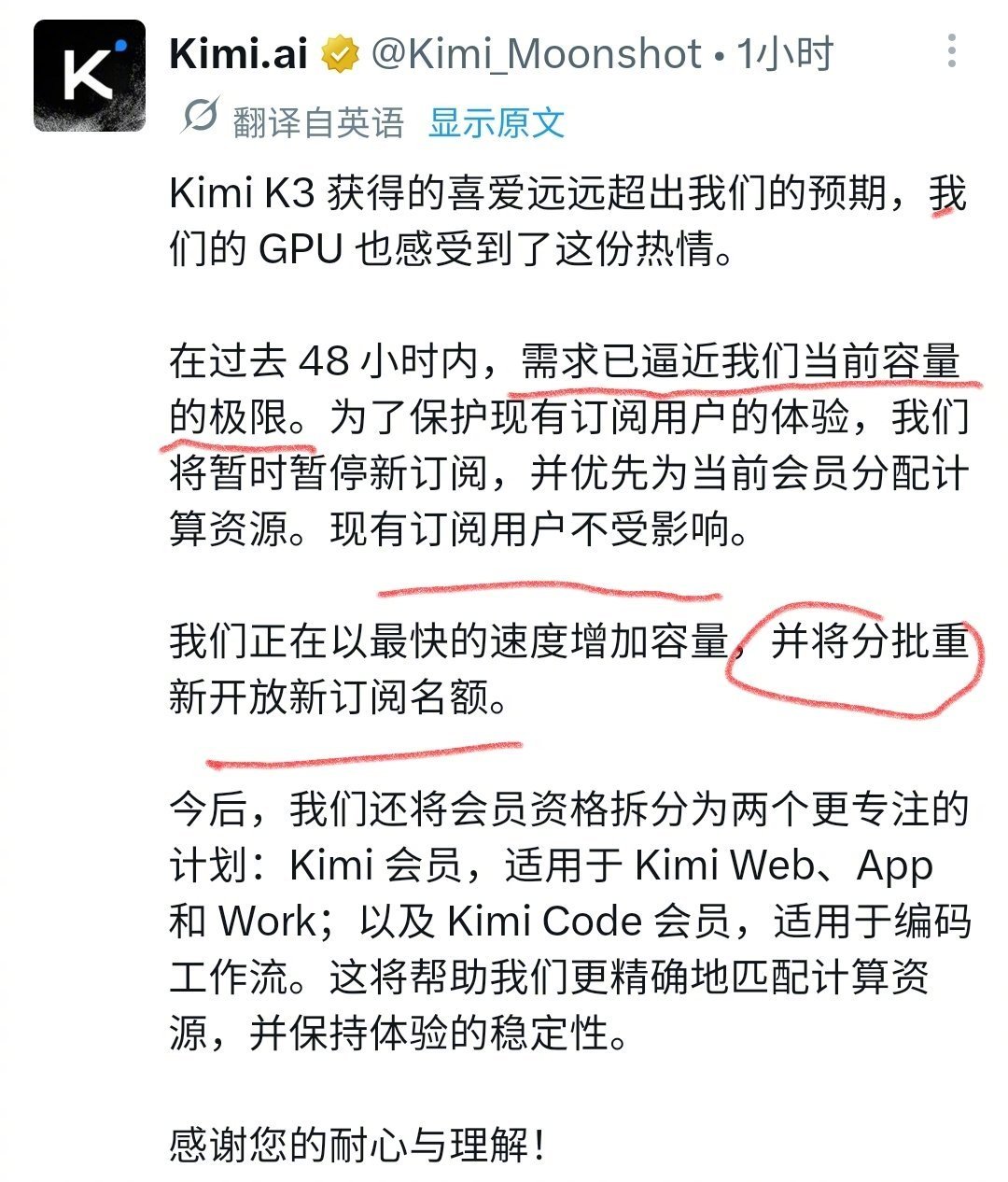

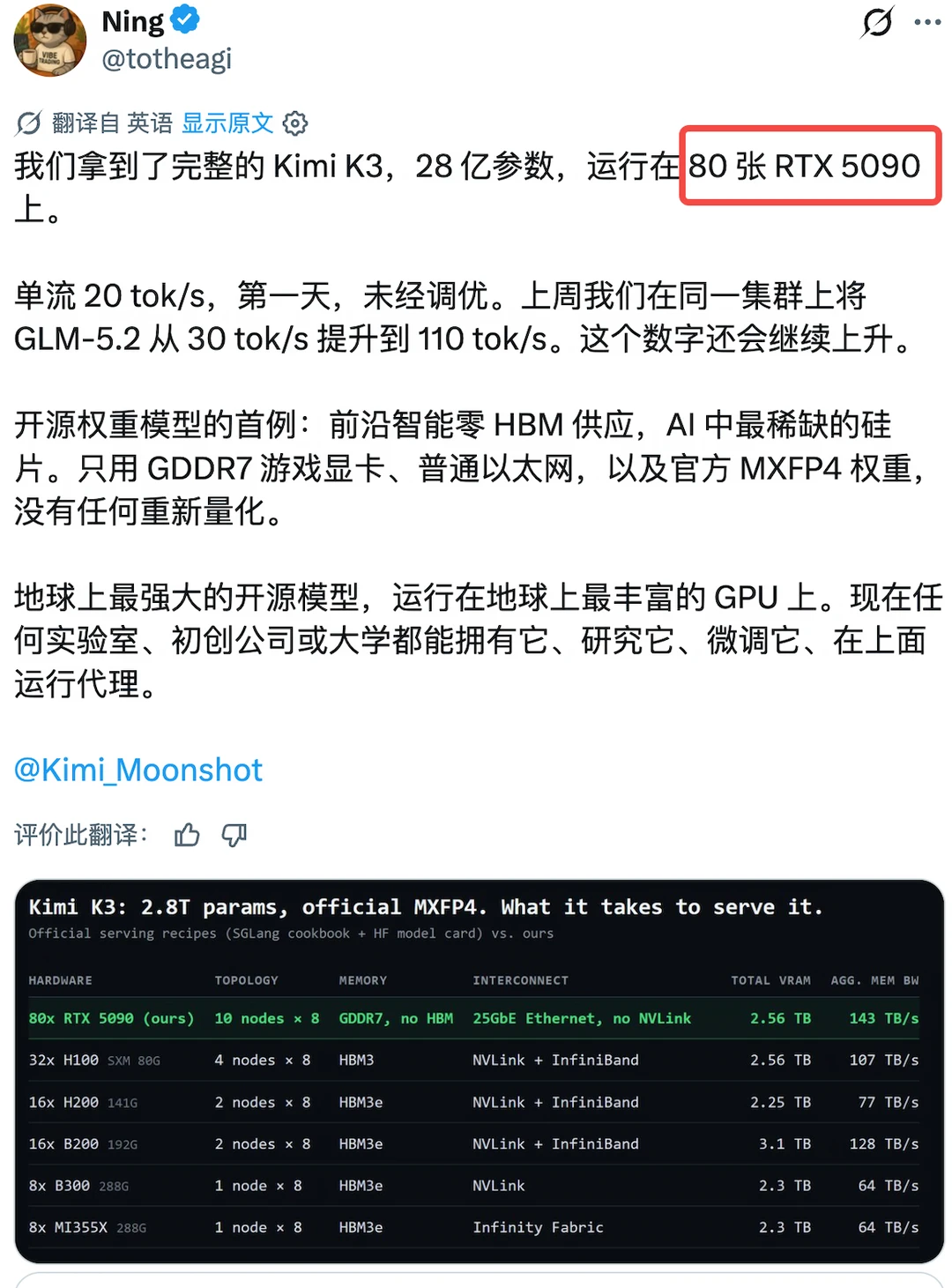
OpenAI称Kimi开源是减速主义外国佬看到咱得大模型水平追上来就开始酸了
OpenAI称Kimi开源是减速主义外国佬看到咱得大模型水平追上来就开始酸了KimiK3对整个AI产业的积极意义:❶架构创新和数据质量打造国产模型新标杆:1)K3定位2.8T开源通用模型,主攻长程编程、Reasoning推理、知识工作和视觉理解等,在ArtificialAnalysis的IntelligenceIndex中Rank3、AgenticIndex中Rank3和ArenaFrontendCode中Rank1;2)K3是国产模型在通用场景和性能的双重新标杆,在游戏开发/CAD/反编译、深度研究报告可视化、严谨知识工作、EDA模拟、视频剪辑等任务上接近Fable5水平;3)K3在长程Agent任务上表现优异,其GPUKernel优化、从零构建GPU编译器MiniTriton、48小时自主芯片设计、2小时完成研究员1-2周的科研编程、3D游戏开发等案例都刷新了产业对开源模型long-horizonagency能力的预期;❷超大参数MoE开源模型将释放CSP和国产超节点红利:1)无所谓算力通缩,K3作为的一个2.8T参数量的超大稀疏MoE(896激活16),仅权重就占用>1.5T的HBM容量(MXFP4下),并采用了极其稀疏的专家并行方案(WideEP),推理Infra对scale-up域的容量和带宽要求极高,需要部署在64卡以上的超节点上做推理;2)腾讯/华为/阿里/Vercel/OpenRouter等已率先完成K3模型上线,已有国产芯片完成自部署适配和模型上线,预计更多hyperscaler和neocloud厂商将完成模型接入、并在7/27的权重开放后完成自有算力适配和部署;3)国产超节点在算力调度池化、PD+vLLM、Mooncake分离式推理、分布式KVCache池、多级缓存&缓存降级等方案上的架构适配和大规模生产落地将进一步享受开源模型的红利,随着Infra推理调度的进一步优化和超节点的商业化,CSP和国产算力将进一步享受顶级开源模型的利润再分配机遇;❸K3在Infra架构和模型性能上仍有优化空间:1)K3默认max思考强度的token消耗超过常规模型,指令模糊时的"过度主动"既有行为失控风险、也进一步推高消耗;2.8T级权重带来极高部署门槛,限制非数据中心算力的利用;实测Output62TPS低于同档模型中位数(72TPS,但TTFT1.99s反而占优);2)用户反馈缓存保留仅10分钟,可能系KDA快照缓存只能精确续写、无法像PagedKV部分复用,命中语义存在架构级差异;而保留时长偏短更可能是快照适配在Infra侧尚未成熟的工程问题;3)当前Agent框架须完整回传历史思考,不适用级联调度下的多模型切换场景;SwarmMax在K3规模下的调度稳定性尚待第三方验证;❹K3的发布对产业的影响显然是更积极的:1)SOTA模型之间的竞争正在加剧。Anthropic近期已持续加大让利(Fable5以50%额度常驻Max订阅、CC周额度上调50%并延长至8/19),GPT-5.6与K3的推出将使其高份额&高毛利面临更直接的竞争压力。但“模型能力天花板远未到顶”是产业里的共识,SOTA模型的交替领先不仅利好上游算力的叙事,也能催使更SOTA的模型早日推出,并加速产业红利进一步向下游应用传导;2)CSP凭借其算力规模效应和生态粘性逐渐掌握了未来模型的分发权和下游应用的拓荒权,将扮演产业趋势里“承上启下”的关键角色。开源模型的崛起和用户数据主权意识的唤醒,正在让CSP与闭源模型公司在生产级的推理市场中占据上风,同时也意味着将Anthropic的ARR作为跟踪行业景气度的唯一指标将不再可取,后续CSP的表述口径&数据披露将会更加关键。


算力芯片需求只会增长,不会减弱,KimiK3的KDA机制提高注意力效率但将需
算力芯片需求只会增长,不会减弱,KimiK3的KDA机制提高注意力效率但将需要更多的GPU、HBM、DRAM和网络而非更少!这已经明确说了,超级AI人工智能大模型参数与推理相关数据的发展,需要更多的gpu算力芯片,不会是减少,而上周中国最大的AI人工智能大模型已经被全球是开源型的大模型!所以AI人工智能越发展越庞大,需要的算力芯片就越来越多,所以AI基础底座就是大规模的在建设数据中心以及算力中心,包括服务器!因为未来的智能体时代以及物理AI就需要这些来进行高速运转与发展!可以AI人工智能的发展,少不了算力需求以及数据储存,未来更是离不开电力能源的需求!


#问一次ChatGPT地球付出多少代价#【问一次ChatGPT,地球要付出多少代
#问一次ChatGPT地球付出多少代价#【问一次ChatGPT,地球要付出多少代价?】当你每一次点开ChatGPT时,千里之外的数据中心就在消耗资源——冷却水、电力、算力。单次AI请求的消耗微不足道,但乘上每天数十亿次的使用量,数字将触目惊心。2024年,全球数据中心耗电415太瓦时,占全球用电量的1.5%。到2030年,这一数字将翻倍,相当于日本全国一年的用电量。再加上芯片里的稀有矿物、堆积如山的电子垃圾、不断攀升的水消耗——AI的能耗究竟会对环境产生多大影响?这个问题亟须正视。与此同时,AI发展也带来了巨大的环境效益。AI技术可帮助优化电网调度、提升可再生能源预测精度,推动传统高耗能行业的生产流程升级,还能为气候变化建模、极端灾害预警提供更为精准的技术支持。这种“双刃剑”属性,让AI的环境影响讨论变得更加复杂。另一个不容忽视的问题是,在AI治理的讨论中,美欧长期占据主导:硅谷定调,布鲁塞尔立法,全球跟着走。全球南方国家作为AI产业链的资源提供者、新兴市场,却很少能发声回应AI给自己国家带来的环境影响,更难以参与到全球AI环境规则的制定过程中。今年7月在日内瓦举行的联合国AI治理全球对话开幕式上,一份白皮书打破了这种单声道叙事,开始郑重回答人工智能与环境之间的关系。这份由金砖国家三个大国的重要智库——国家高端智库复旦大学中国研究院、俄罗斯自然与人民基金会、印度帕勒基金会联合撰写,联合国互联网治理论坛环境动态联盟支持,并在这次联合国对话中发布的《人工智能与环境白皮书》,把人工智能的环境足迹与环境效益纳入同一分析框架、系统探讨人工智能与国际可持续发展的关系,也是金砖国家智库首次联手,把“全球南方”的视角带入了AI环境治理的讨论桌。著名经济学家杰弗里·萨克斯教授为《白皮书》作序时,称之为“具有里程碑意义的文件”。7月18日,在2026世界人工智能大会期间,由复旦大学中国研究院主办的《人工智能与环境白皮书》国际研讨会上,来自俄罗斯、印度和中国的专家,继续探讨人工智能与环境的关系。2012年的时候,训练一次AlexNet会排放0.01吨二氧化碳,这个量几乎可以忽略不计。2020年,训练一次GPT-3,排放量达到588吨。2023年的GPT-4,这个数字来到了5184吨。2024年的Llama3.1405B,数字变成了8930吨……很难想象,2030年我们面对的AI能耗会到什么地步?但训练AI只是这个问题的冰山一角。Facebook的实测数据显示:在已部署的AI系统中,推理贡献了约65%的碳排放,训练只占35%。随着AI走向亿级用户,这个比例只会更悬殊。MistralAI第一次把单次查询的账单摊开:一个400-token的回复,会排放1.14克的二氧化碳,消耗45毫升的水——水,可能是AI账本里最被忽视的一行。OECD预测,到2027年,AI相关用水量可达66亿立方米,这相当于英国半年的用水总量。更值得警惕的是:数据中心往往建在水资源最紧张的地方。以印度为例,印度有6亿人面临高至极端水压力,班加罗尔作为印度的科技中心、数据枢纽,却面临着地下水枯竭、未来净可用水量归零的严峻风险。中国“东数西算”把算力往西部赶,某种程度上是对这种矛盾的回应,但全球范围内,AI的水消耗仍在以一种近乎不可见的方式加剧区域资源竞争。除了水以外,硬件本身的代价,同样惊人。一台2公斤的电脑,生产需要约800公斤原材料——稀土、锂、钴、镓、铜。这些矿产的开采和冶炼,不仅涉及栖息地破坏、水污染和长期生态毒性,其环境影响还不成比例地集中在全球南方。等这些原材料被制成GPU后,在数据中心里通常只有3到5年的寿命。更新周期越短,淘汰越快,废弃的硬件堆积成山——2022年全球电子垃圾已达6200万吨,而AI专用设备产生的废料尚未被单独统计。算力越强,硬件迭代越快,电子垃圾的增长曲线只会更陡。


连续两年斩获WAIC最高SAIL大奖!中兴OEX光电融合超节点打通国产算力闭环
连续两年斩获WAIC最高SAIL大奖!中兴OEX光电融合超节点打通国产算力闭环一、核心事件7月17日2026世界人工智能大会,中兴通讯联合曦智科技、壁仞科技、沐曦股份、燧原科技、天数智芯,凭借OEX+dOCS国产高性能Matrix超节点再度拿下SAIL之星大奖,实现2025-2026连续两年斩获该顶级奖项,方案技术实力获行业权威认证。二、三大核心颠覆性技术创新1.架构创新:OEX正交无背板零线缆设计首创正交直连架构,彻底取消机柜数千根铜缆,计算托盘与交换托盘垂直交叉直连,大幅缩短SerDes传输链路,消除线缆带来的信号插损;单机柜最高支持128卡高密度集成,等同于一台巨型GPU。配套“算力集装箱”前置开发模式,芯片厂商整机研发周期由18-24个月压缩至3-6个月,降低国产GPU商业化落地成本,技术架构可适配未来6-8年算力迭代需求。2.互联创新:光+电融合双层组网-柜内:自研57.6T高密电交换芯片,满足单机柜多卡低时延协同;-柜间:分布式dOCS光交换动态重构拓扑,减少多层光电转换损耗,集群通信时延低至百纳秒,可平滑扩容至十万卡级超大规模算力集群,适配万亿参数大模型训练。3.生态创新:开放解耦多芯协同底座不绑定单一算力芯片,全面兼容壁仞、沐曦、燧原、天数智芯等全部国产GPU,支持异构芯片统一调度,多卡协同实现集群性能1+1>2;打通AI芯片-OEX服务器-算力集群全自主可控产业链闭环,整体大幅降低智算中心TCO。三、产业落地价值1.适配国内智算中心算力紧缺现状,高密度、低功耗、易扩展的特性完美匹配当下AI算力集群建设需求;2.坚持“沪设沪造”本地化落地,为上海人工智能产业提供全栈国产算力基础设施支撑;3.光电融合超节点确立国产算力互联全新技术范式,解决传统线缆架构损耗高、密度低、运维复杂的长期行业痛点。四、产业链核心合作企业1.中兴通讯:整机架构、自研交换芯片、算力集群系统方案总牵头方;2.曦智科技:dOCS分布式光交换芯片核心供货;3.壁仞科技、沐曦股份、燧原科技、天数智芯:国产GPU适配合作伙伴。行业总结AI算力竞争已经从单芯片比拼转向整机集群系统能力竞争,OEX+dOCS超节点依托无线缆高密度架构、光电融合高速互联、全开放国产芯片生态,成为国产智算基础设施标杆方案。连续两年拿下WAIC最高奖项,印证其技术壁垒与商业化落地潜力,完整带动服务器、光交换、国产GPU整条算力产业链景气上行。以上信息仅供参考,不构成投资建议。





白天跌停晚上业绩暴涨!PCB这波操作把我看愣了老铁们,今天说个稀罕事。7月13号
白天跌停晚上业绩暴涨!PCB这波操作把我看愣了老铁们,今天说个稀罕事。7月13号,A股PCB板块一片惨绿。华正新材、生益科技、金安国纪,这些大牛股一个接一个往跌停板上摁。我盯着屏幕,心想:这行业是暴雷了吧?资金跑得这么凶。结果收盘后,这帮“难兄难弟”甩出半年报,直接把我震住了:金安国纪,净利润预增最高1063%!生益科技,净利润翻倍,光二季度就比一季度多赚了八成!白天被摁在地上摩擦,晚上业绩炸穿天花板。这市场是疯了吗?还是说,咱对PCB这三个字母,压根就没看懂过?一、别再把PCB当“破电路板”了很多人一听到PCB,脑子里就是那种绿油油的板子,觉得是低端制造业,没啥技术含量。如果现在还这么想,那这轮AI大行情,你可能真的白看了。PCB到底是啥?说人话——所有电子设备都离不开它,相当于电子产品的“地基”和“神经系统”。你手机里有,电脑里有,冰箱电视里也有。但AI服务器里的PCB,跟咱们普通家电里的,完全不是一回事。普通服务器PCB就8到12层,AI服务器直接干到20层、30层以上。层数越多,布线越密,信号传输越快,技术门槛也越高。中信建投的一份研报就说得很直白:算力需求正成为PCB行业最重要的结构性增量,AI服务器从CPU转向GPU集群,全面抬高了PCB的技术要求。简单讲——AI算力越猛,对PCB要求越高,PCB就越值钱。这不是我说了算,是数据说的。金安国纪自己解释业绩暴增原因时就提了八个字:“覆铜板供不应求,价格持续上涨”。供不应求、价格上涨。这哪是夕阳产业?分明是卖方市场。二、数字不会骗人:这帮“卖铲子”的赚嗨了咱们直接看数据,感受下这个画风:金安国纪:上半年净利润7.30亿到8.20亿元,同比增长935%到1063%。你没看错,十倍增长。鼎泰高科:净利润增长300%到338%。这公司干啥的?给PCB厂提供精密刀具的。淘金热里卖铲子的逻辑,听过吧?金挖得越多,铲子卖得越火。生益科技:净利润30.99亿到32.98亿元,同比增长117%到131%。子公司生益电子直接受益于AI算力,“智能算力中心项目”高效落地并快速释放效益。一圈看下来,十几家公司业绩集体井喷,这已经不是个体经营好坏的问题了。我身边有个老股民,最爱干的事就是追热点。今天AI芯片,明天机器人,追得不亦乐乎,但账户还是绿的。昨天他问我:“PCB不就是个破电路板吗?能有多大花头?”我把数据甩给他看,他沉默了。很多时候,咱们炒股最大的敌人不是市场,是自己的偏见。三、看懂“卖水人”逻辑,比追热点重要一万倍这轮PCB爆发的底层逻辑,其实特简单——AI算力产业链的“卖水人”效应。你想想,不管是英伟达的GPU,还是国产的算力芯片,只要服务器在造、数据中心在建,就离不开高端PCB。而且技术越升级,PCB层数越多、材料越贵、利润越高。PCB跟锂电池、光伏有本质区别。锂电池的化学性能有天花板,光伏的转换效率也有物理极限。但PCB是电子技术的载体——芯片没到头,它对PCB的要求就不会停。从CPU到GPU再到AI芯片,每一次升级,都带来更复杂的封装、更密集的连接、更高端的PCB需求。只要AI没到头,PCB的需求就不会饱和。这叫什么?这叫确定性。普通投资者最大的优势,不是资金,不是信息,是时间。与其在那些看不懂的高位概念里搏杀,不如找找产业链上游“闷声赚大钱”的供应商。当年美国淘金热,真正赚大钱的不是挖金子的,是卖牛仔裤、卖铲子的人。今天的PCB,就是AI算力浪潮里那条“最结实的牛仔裤”。用耐心守候认知差带来的回报,时间是优秀公司的朋友。---风险郑重提示:本稿件所载全部内容仅依托市场公开信息归纳整理,仅为客观信息展示,不代表任何投资推介、交易建议与价值判断。资本市场波动风险显著,任何投资行为均存在本金亏损可能性,恳请各位投资者结合自身风险承受能力独立研判、理性投资。看完觉得有启发,点赞、收藏、关注走一波,咱们下期接着聊干货!





科技股迎来新的赛道,下半场的主线或许就是CPUAI炒作时代(堆GPU)结束,实用
科技股迎来新的赛道,下半场的主线或许就是CPUAI炒作时代(堆GPU)结束,实用落地时代(CPU+各类端侧芯片)开启,国产CPU迎来AI行业的增量红利。AI时代已经告别单纯比拼显卡数量、堆超大算力集群的内卷阶段,行业重心转向赚钱、落地商用,行业估值逻辑重塑:不再只看GPU供货量,CPU、端侧专用芯片、行业推理方案都具备长期增长逻辑。十万卡全国产集群接入国家超算互联网,是数字基础设施自主可控标志性工程。大规模AI产业不再受制海外芯片供给限制,国家层面算力安全、数据安全保障能力提升,后续政企AI项目会优先采用国产CPU整机。单纯GPU炒作降温,国产服务器CPU、嵌入式芯片、边缘推理硬件成为新主线;市场重新定价海光等国产CPU企业:市场之前只把它当作普通服务器芯片厂商,现在确认深度绑定AI下半场刚需,业绩增长预期上调;端侧推理、行业AI应用、向量数据库配套硬件迎来估值修复机会。






基金科技继续王朝咯设备芯片封测轮番上阵我说了长鑫科技上市利好设备利好材
基金科技继续王朝咯设备芯片封测轮番上阵我说了长鑫科技上市利好设备利好材料注意下如果设备不反包新高那么就得继续落袋中午沐曦股份临时辟谣导致回落挺多但也不影响我进gpu继续搞科技吧目前主线还是半导体还有就是咱们惠新里面俩个股停牌影响收益但是后面大概率会有补涨的周五应该拓荆科技就能复牌了a股

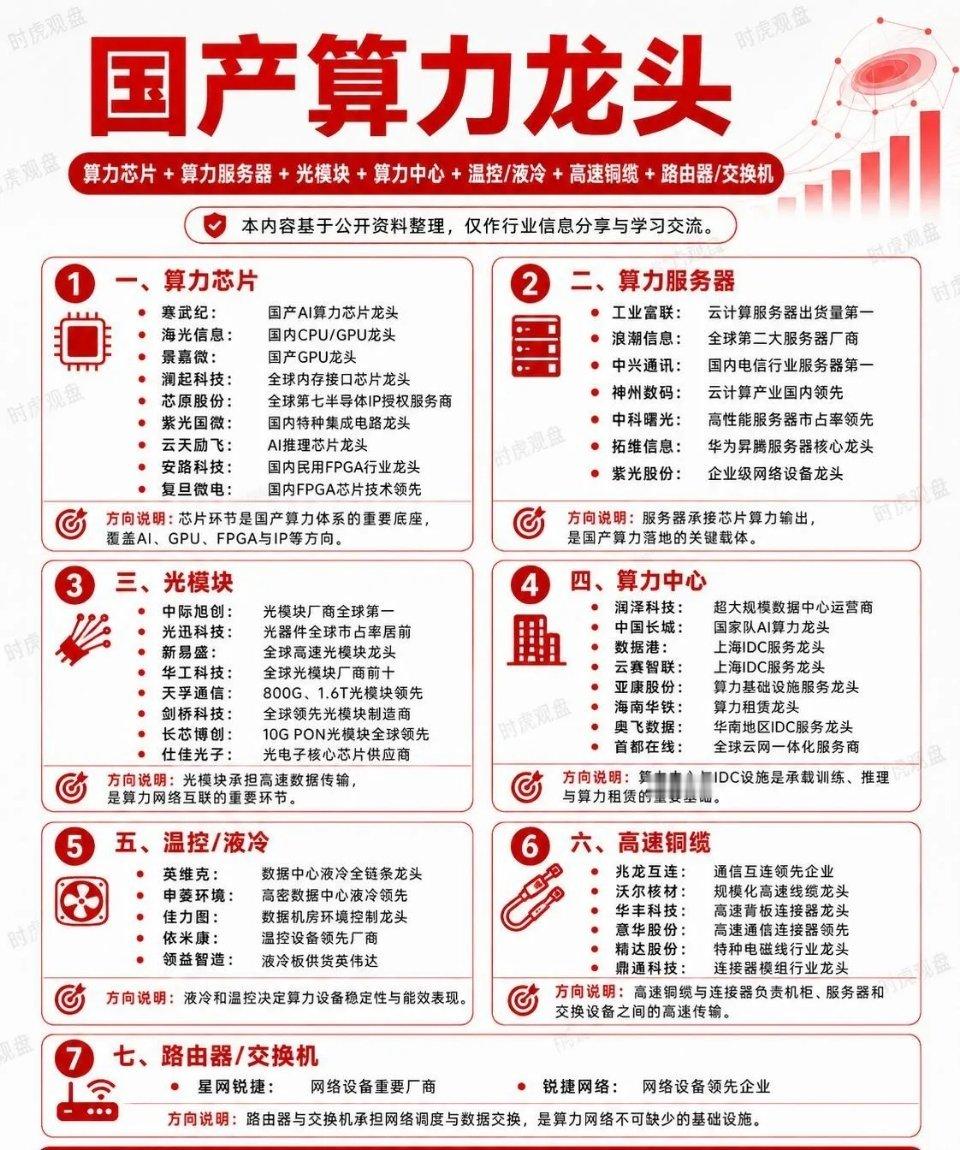
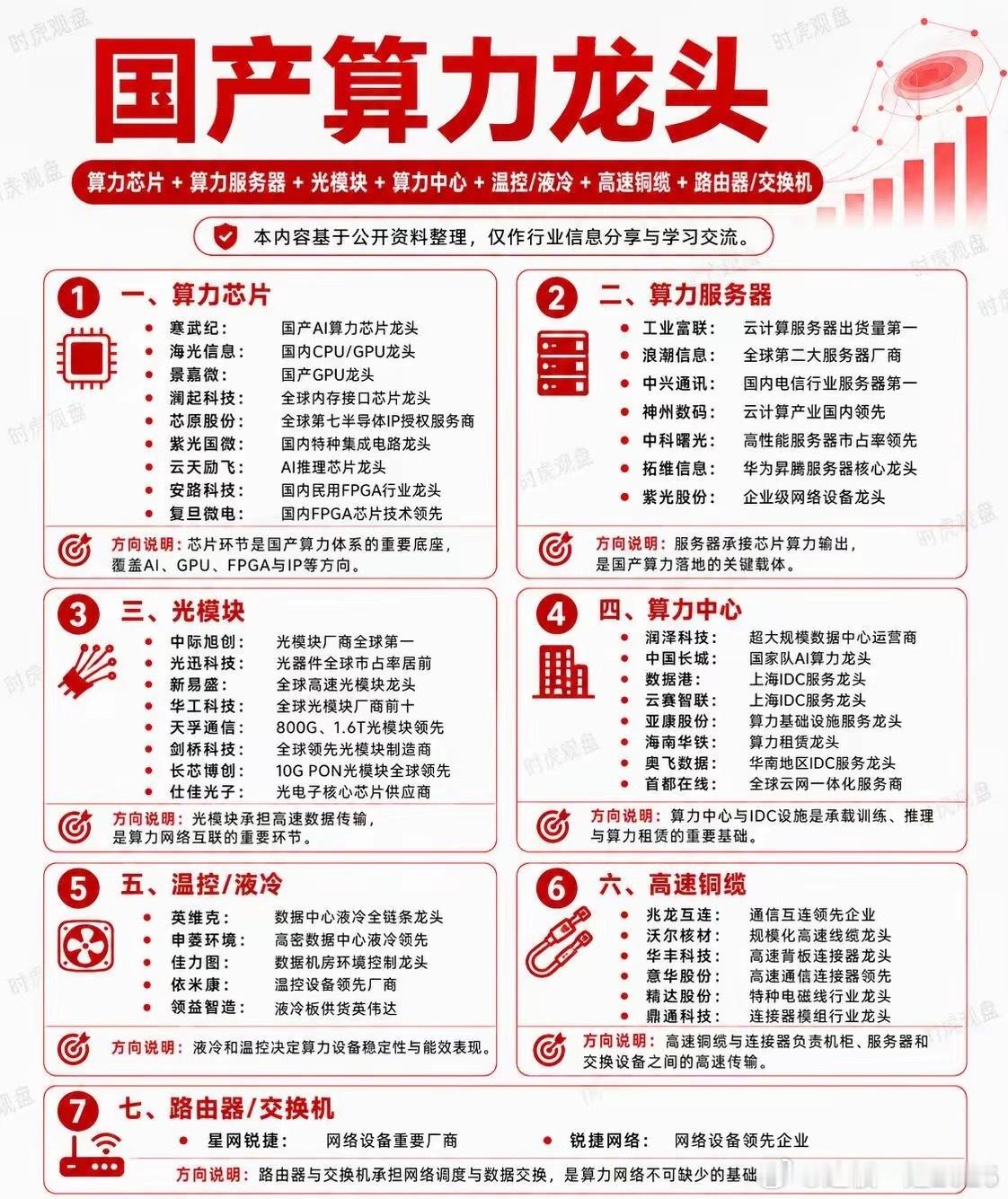
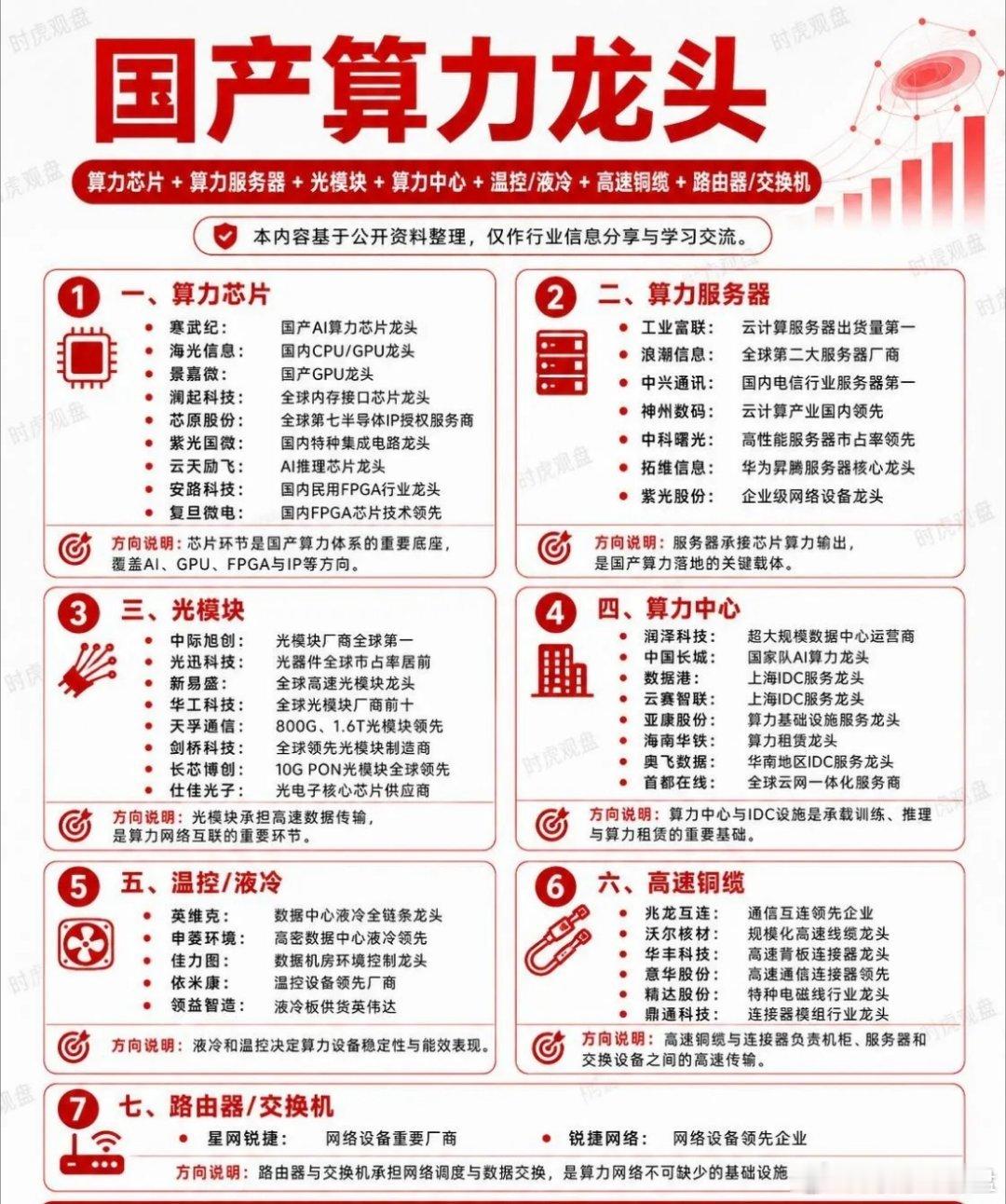
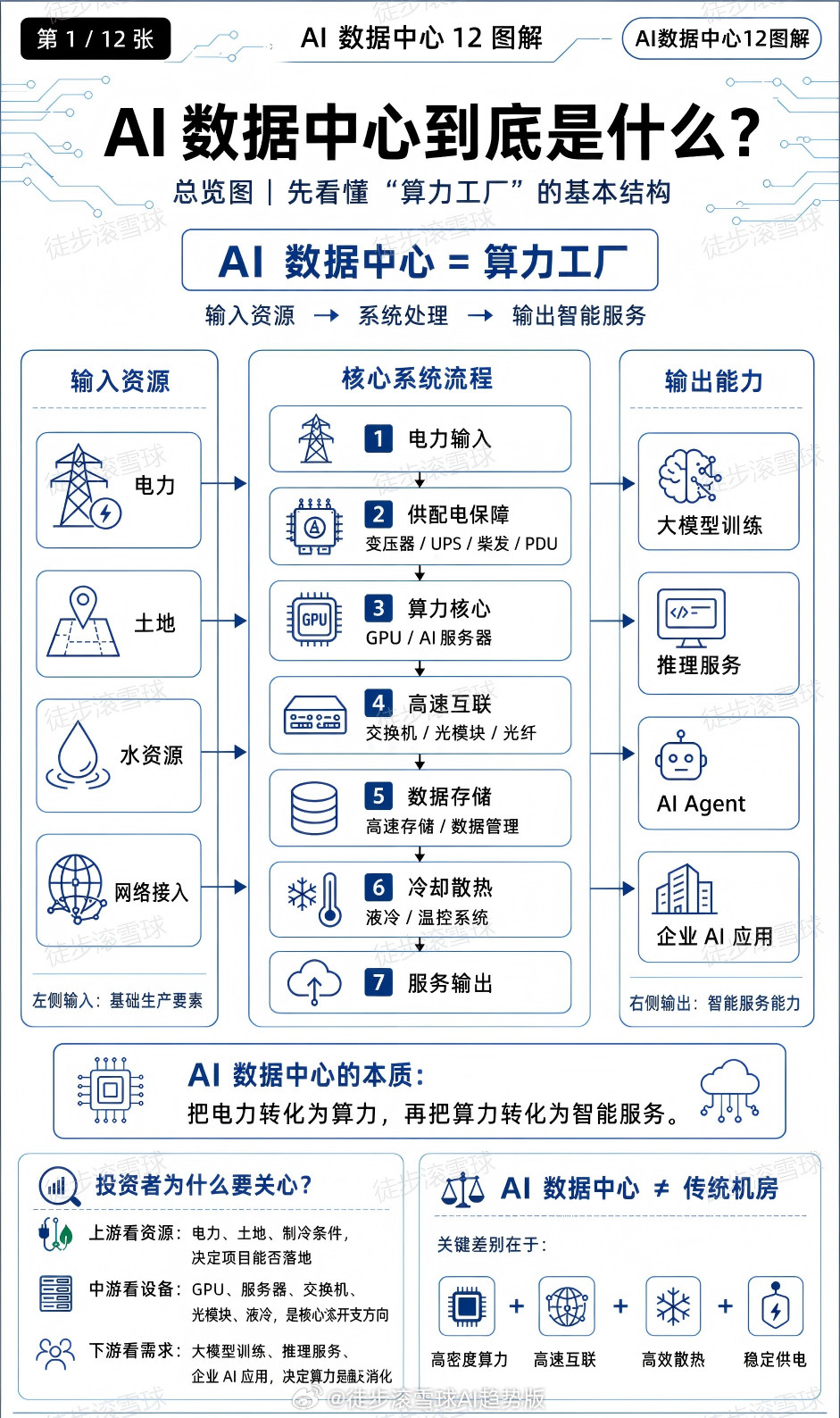
红利AI基金etf12张图读懂AI数据中心:从电力到算力,从硬件到应用AI数
红利AI基金etf12张图读懂AI数据中心:从电力到算力,从硬件到应用AI数据中心不是机房,而是Token工厂。AI数据中心的本质,不只是把电力转化为算力,而是把算力进一步转化为Token、API调用和企业生产力。最近两年,AI产业链越炒越细:从大模型到算力,从GPU到光模块,从液冷到电力设备,再到PCB、变压器、储能和数据中心。很多人的问题不是“不关注AI”,而是越看越乱:到底什么是真需求?什么是蹭概念?AI数据中心为什么会同时拉动这么多行业?所以我整理了这组图,想用更直观的方式,把AI数据中心这件事讲清楚。看懂这个框架,才知道为什么电力、GPU、光模块、液冷、PCB、存储都会被卷进来;也才能分清楚,哪些环节是真正的核心瓶颈,哪些只是普通配套,哪些又可能只是短期概念炒作。$半导体ETF国联安sh512480$$兆易创新sh603986$$寒武纪sh688256$




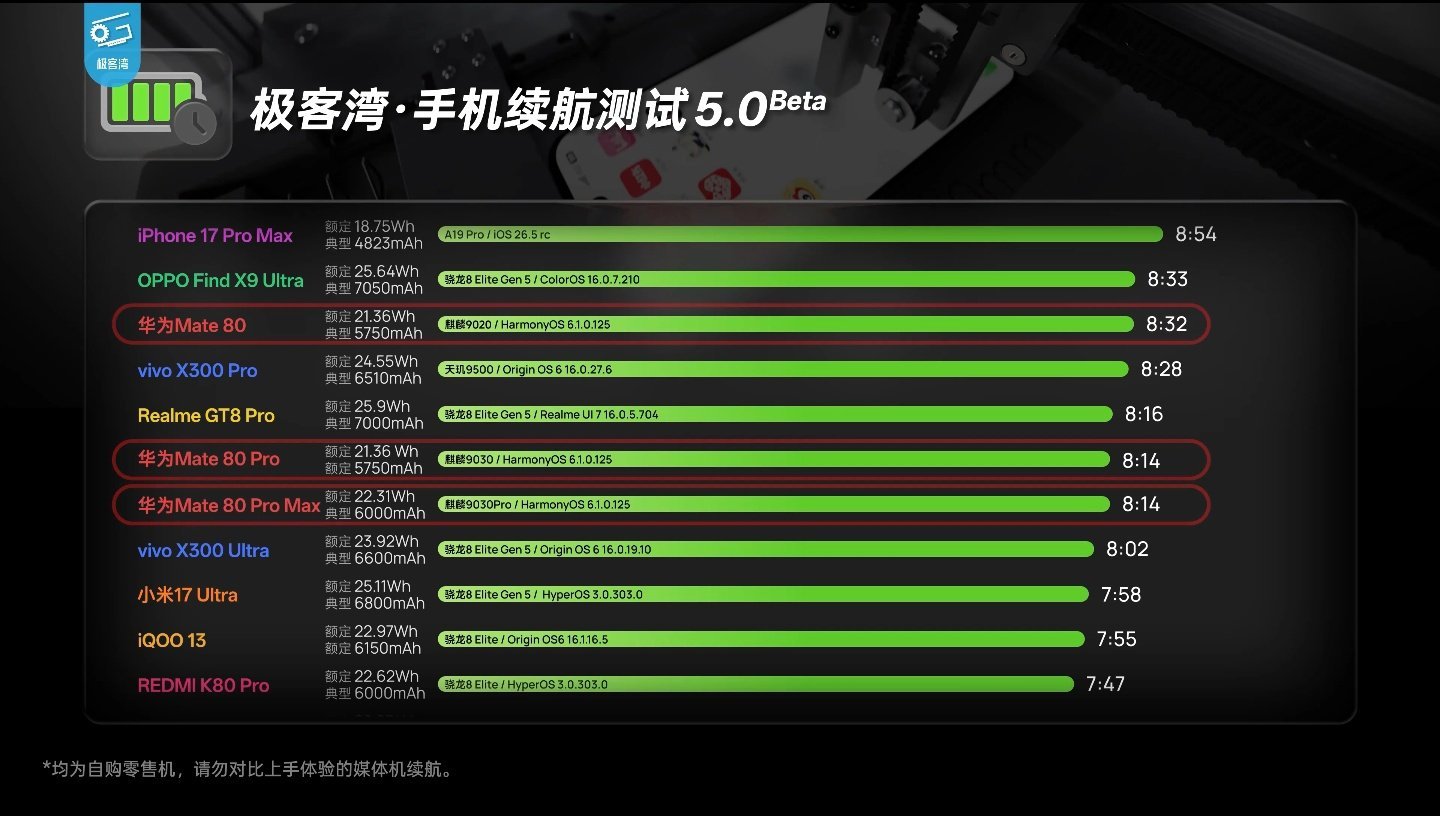
【华为Mate80Pro性能解禁:麒麟9030ProGPU相比
【华为Mate80Pro性能解禁:麒麟9030ProGPU相比9020提升76%,《原神》能效表现优于高通骁龙8Gen3】华为去年发布了Mate80系列旗舰手机,搭载华为自研的麒麟9030及麒麟9030Pro处理器。今日,B站up主放出了一期针对华为Mate80Pro的性能分析报告。据介绍,这两款芯片均基于同一种Die,估算约有150亿晶体管,规模与苹果A15、高通骁龙8Gen2接近。其中,满血版的麒麟9030Pro采用9核14线程架构,包含一颗2.75GHz超大核、四颗2.27GHz大核及四颗1.72GHz小核,并集成6核马良935图形处理器。麒麟9030则在此基础上屏蔽一颗CPU大核变为8核12线程,并采用了5核马良935AGPU。架构方面,麒麟这代大核与小核变化不大,主要对超大核寄存器深度及乱序执行窗口进行了微调。缓存上,超大核L2缓存翻倍至2M,5颗大核共享的L3从10M升级到12M,SLC缓存也提升至12M。在能效测试中,极客湾移植了原生的SPECCPU2017测试,并结合HiSmartPerf高性能模式进行了测试。结果显示,麒麟9030Pro的超大核能效稳步提升,性能接近高通骁龙8+的Cortex-X2核心,虽然仍未超越X2,但差距已非常接近。另外,麒麟9030Pro浮点性能进步更为明显,中频段能效表现出色。多核能效方面,得益于工艺升级和核心数量增加,9030Pro的多核能效曲线落在骁龙8Gen2和8Gen3之间,中低频能效甚至接近8Gen3,相比前代9020提升巨大。GPU方面,马良935架构获得了显著提升,ALU单元相比前代翻倍,算力提升超过200%。在3DMark的SteelNomadLight测试中,9030Pro比9020强了76%,能效曲线与骁龙8+接近。此外,9030Pro的NPU升级为“一大两小”三NPU架构,ISP方案也升级至9.0,基带面积则大幅缩减了31%。在实际应用表现方面,鸿蒙原生版《原神》的表现令人惊艳。Mate80ProMax在804P分辨率下可实现全程60帧畅玩,整机功耗仅4.9W,能效甚至优于8Gen3在720P下的表现。这得益于鸿蒙原生应用去除了冗余代码,以及芯片底层对图形驱动的深度优化。在《王者荣耀》120fps极致设定下,其平均功耗仅3W,能效表现极其出色。对于《异环》等游戏,虽然目前调度策略尚有优化空间,但整体表现已处于行业第一梯队。针对光线追踪技术,麒麟9030Pro集成的马良935GPU首次支持该功能,在《暗区突围》等重载场景下,系统通过针对性的驱动层优化,实现了功耗控制与性能释放的平衡。极客湾指出,Mate80系列的系统流畅度也远超预期。鸿蒙系统配合麒麟9030芯片,通过更智能的调度策略,避免了安卓端常见的“一刀切”限频问题,加上原生应用的高效开发框架,使得交互体验异常顺滑。华为Mate80Pro配备5750mAh电池,Mate80ProMax配备6000mAh大电池。测试数据显示,两款机型在极客湾5G续航5.0模型测试中均取得8.14分的成绩,在一众旗舰中稳稳保持第一梯队级表现。




夜深了,证监会大动作,央行万亿拟回购,下周A股观点来了!一、热点解读①证监会征求
夜深了,证监会大动作,央行万亿拟回购,下周A股观点来了!一、热点解读①证监会征求意见:在拟融资规模不超过净资产20%的前提下沪深交易所上市公司小额快速融资上限从3亿元提升至6亿元。利好A股,特别是科技股和券商。②三部门:调整节能汽车、新能源汽车车船税优惠政策。调整节能汽车、新能源汽车车船税优惠政策。③上游原材料采购成本明显提升充电模块集体涨价15%。④摩根大通:大模型使用与GPU租赁价格齐升AI基建需求仍获支撑。⑤德银:Meta云业务或打开千亿美元级AI投入变现通道。⑥7月6日(下周一)开展1万亿元3个月买断式逆回购,当月到期8000亿,净投放2000亿,终结连续3个月流动性缩量回二、关于A股①今天晚上美股休息,晚间的消息利好比较多,央行的利好消息,释放了流动性,所以A股很难大跌。②利好板块1:AI算力硬件链,Meta/摩根大通验证海外资本开支;充电模块涨价印证半导体产能紧缺;所以继续看好③利好板块2:头部券商流动性宽松利好自营与两融;再融资新规直接增厚投行收入。④利好板块3:充电桩+储能细分:充电模块涨价修复企业利润。⑤对于下周A股,我的观点还是震荡。先反弹后下跌!


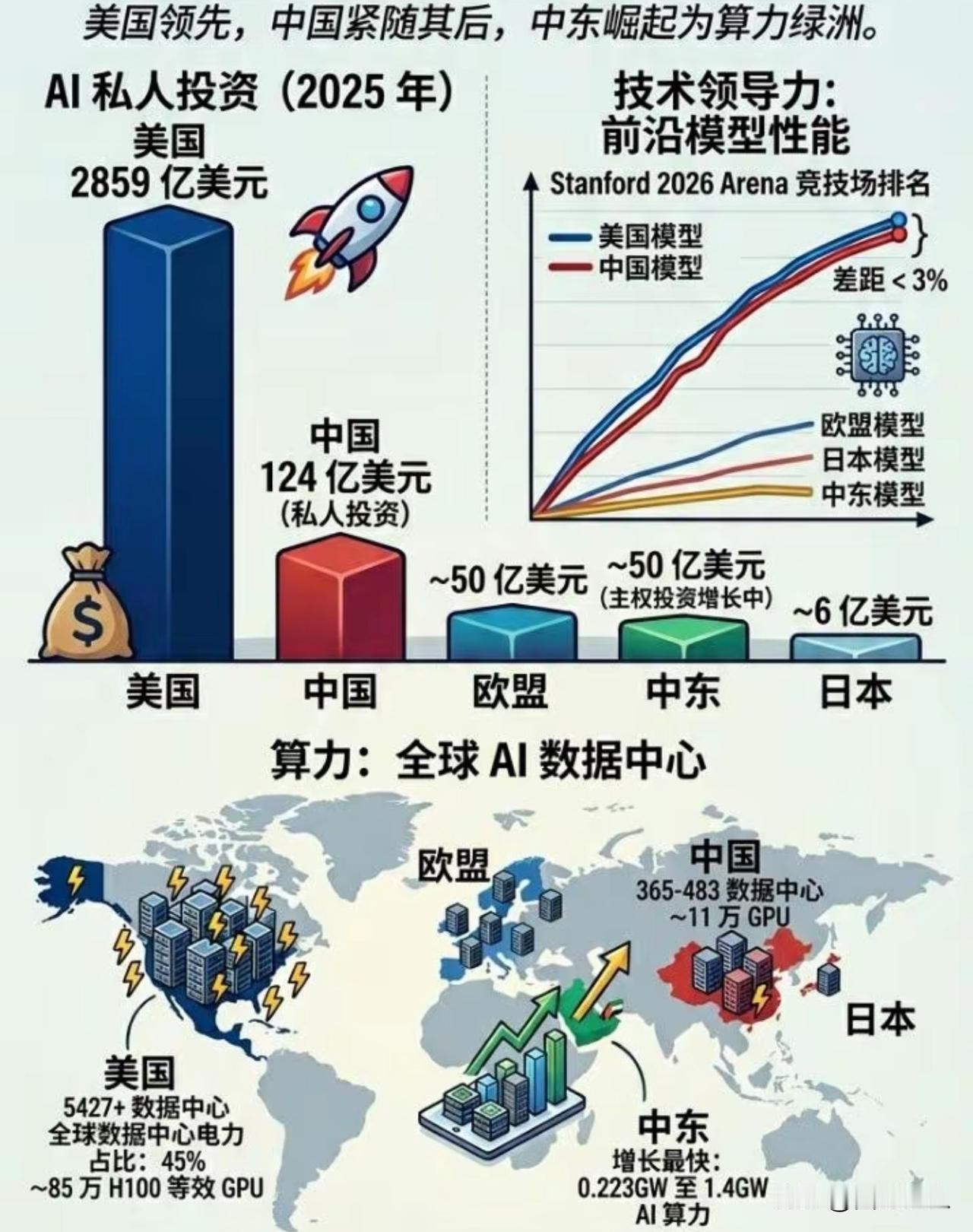
大模型时代,欧洲,日本,韩国,全部被淘汰!大模型时代,实质上就是中美双寡头时
大模型时代,欧洲,日本,韩国,全部被淘汰!大模型时代,实质上就是中美双寡头时代,参数规模万亿以上的,中美占比95%以上。大模型入门门槛,就是算力,也就是GPU,所以一个英伟达的市值,超过任何一个欧洲单一国家。70%留在美国,20%流向中国,只有剩下的10%才由其他国家分食,欧洲,日韩连1%都不到。第二道门槛,就是数据,语言资料库的规模和质量,英语资料库占60%,中文占18%左右,在这个领域下,法语,日语沦为小语种。没有足够的数据支持。第三道门槛,是资本,前期投入巨大,没有任何盈利,能做到的企业,全球寥寥无几。第四道门槛,是人才,全球大算力模型的人才,实质上就是中美之争,因为欧日韩的人才,几乎全部流向美国。中国和美国在相互挖角。当然,其他国家不会被淘汰,只不过没有了话语权,和竞争力,用现成的大模型,专心做场景应用就行了。