[CL]《Is In-Context Learning Learning?》A d Wynter [Microsoft] (2025)
在大规模实证分析中,本文首次系统探讨了自回归大语言模型(LLMs)中的“上下文学习”(In-Context Learning, ICL)是否真正构成一种学习机制,揭示了其能力与局限:
• ICL通过在提示中给出示例(exemplars),无需额外训练即可解决任务;数学上,ICL确实符合PAC学习框架中的“学习”定义,但它依赖模型的预训练知识和示例,未显式编码观察数据。
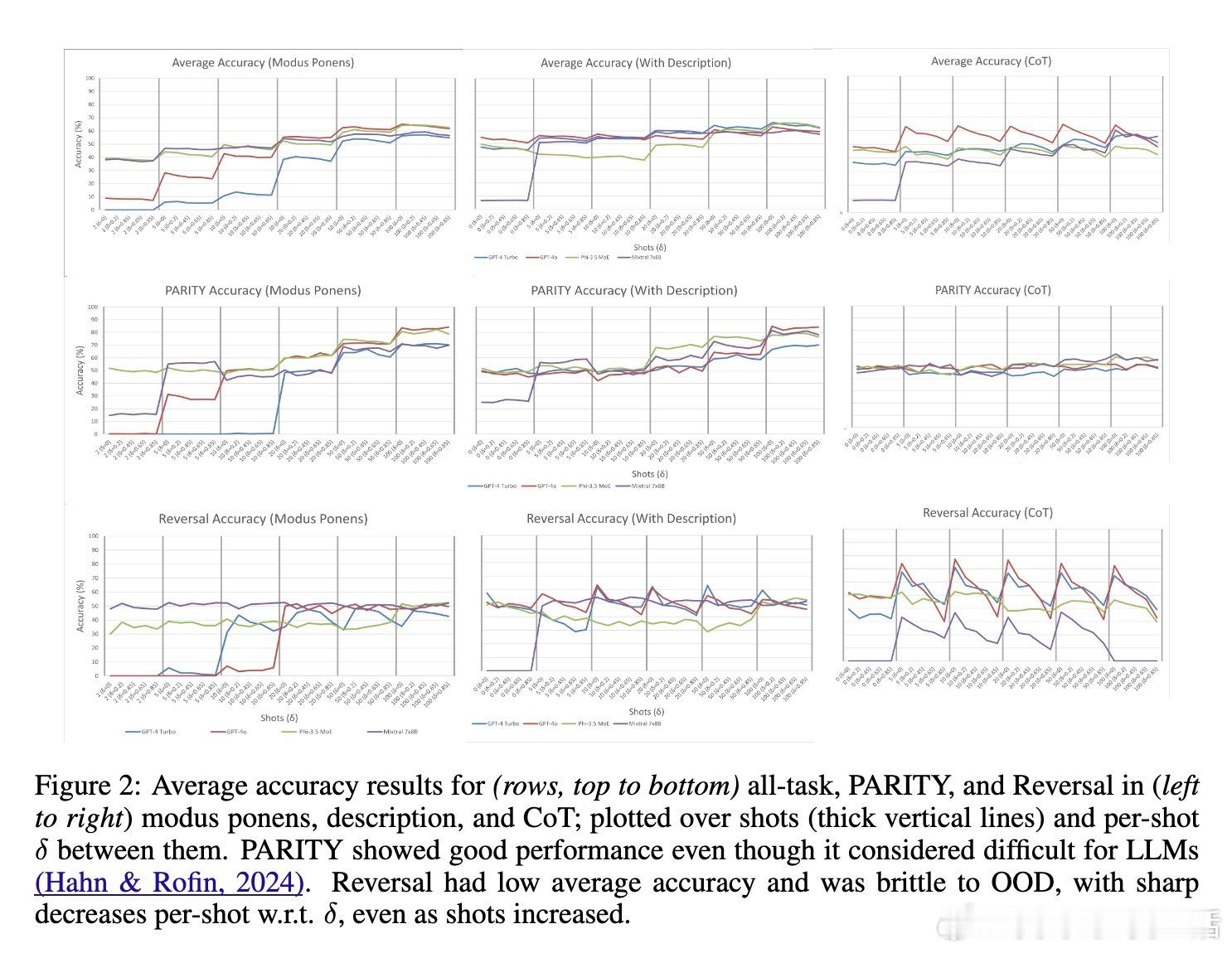
• 实验覆盖4款LLM、9类任务、1.89百万次预测,综合评估了示例数量、提示风格、训练分布、分布漂移(OOD)等因素对性能的影响,发现:
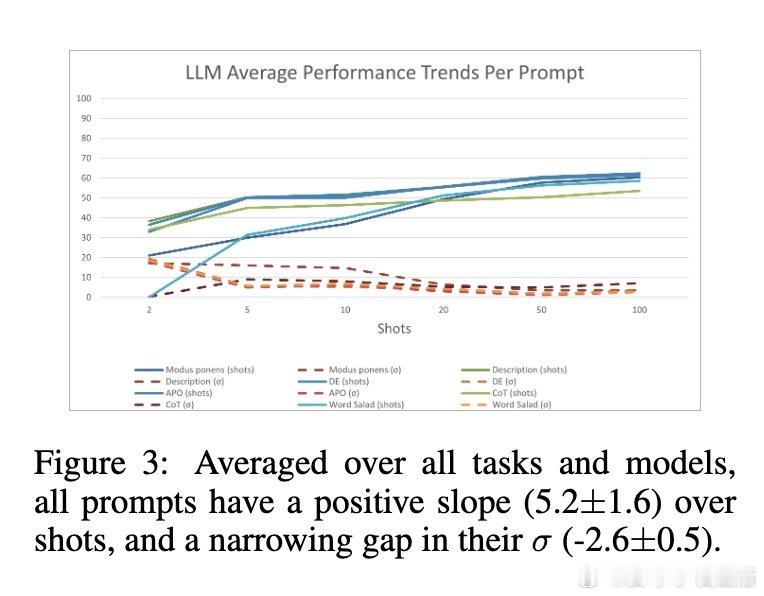
– 大量示例(50-100个)显著提升准确率,且不同模型和提示策略间的差距缩小;
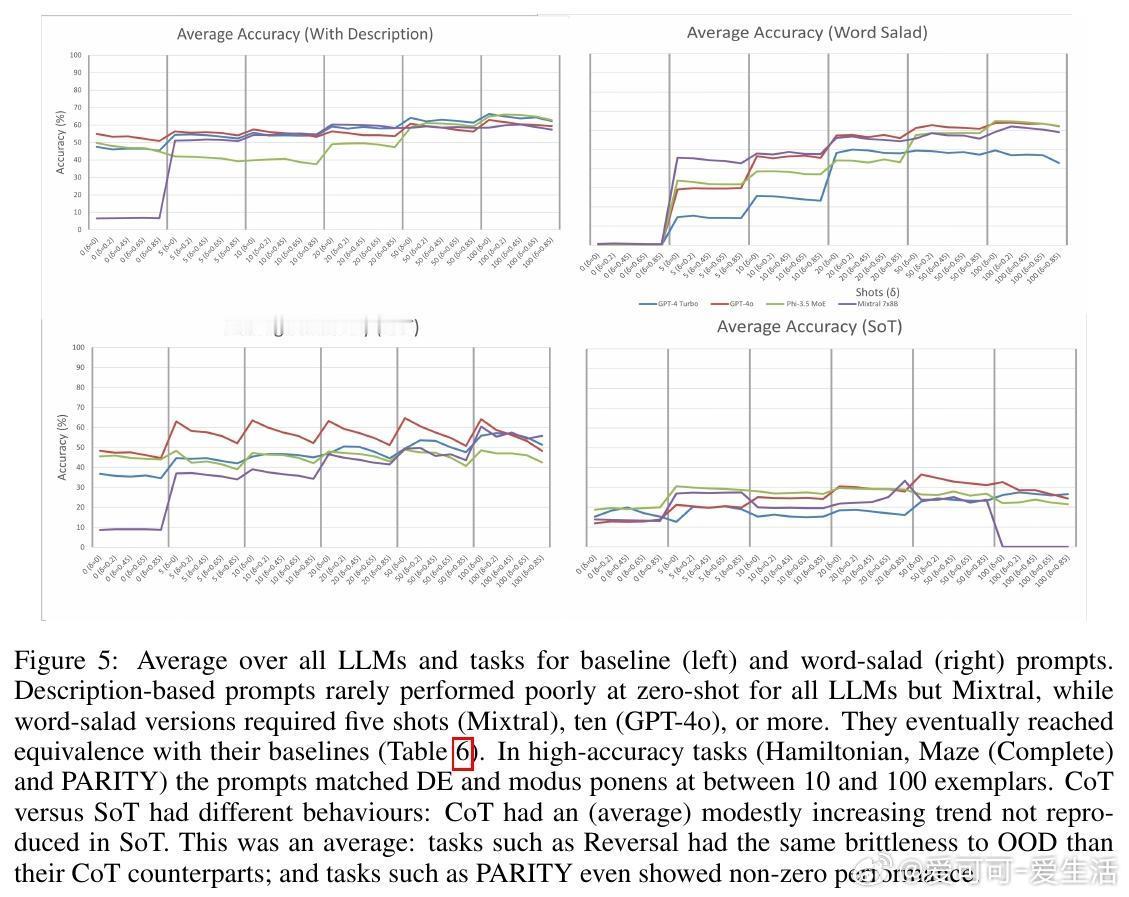
– ICL对训练示例分布的稳健性较好,但对测试时的分布漂移非常敏感,尤其是链式思维(CoT)和自动提示优化(APO)提示;
– 相关任务间表现差异巨大(最高31%),传统方法在部分任务中仍优于ICL平均表现。
• 语义混淆的“词汇沙拉”提示在示例足够多时能达到与原始语言提示相近的效果,表明ICL更依赖统计规律而非语义理解;示例顺序和标签比例影响有限,但随机化示例降低表现。
• ICL表现的限制源自其“临时编码”机制,即模型通过统计特征而非深层特征关系进行推断,导致跨任务的泛化能力受限。
心得:
1. ICL本质上是一种学习过程,但其泛化能力高度依赖于示例的代表性,难以稳健应对分布外输入。
2. 大规模示例提供是提升ICL性能的关键,远超先前认为的“少量示例”即可解决任务的观点。
3. 评价LLM能力需多样化提示和分布测试,单一任务或提示容易产生误导性结论。
详见🔗 arxiv.org/abs/2509.10414
人工智能大语言模型机器学习上下文学习自然语言处理