[CL]《Reasoning Under Uncertainty: Exploring Probabilistic Reasoning Capabilities of LLMs》M Pournemat, K Rezaei, G Sriramanan, A Zarei... [University of Maryland] (2025)
大型语言模型(LLMs)在概率推理上的表现揭示了它们的潜能与局限:
• 研究首次系统评估了LLMs对离散概率分布的推理能力,设计了模式识别(mode identification)、最大似然估计(MLE)和样本生成三大任务,涵盖频率分析、边缘化和生成能力。
• 大型模型(如Llama3.3-70B、GPT-4.1-mini)在所有任务中表现优异,尤其在样本生成上甚至优于Python随机采样器,显示出惊人的生成质量。
• 条件概率推理任务普遍难度更高,模型准确率明显下降,暴露出它们在复杂条件推断上的短板。
• 模型对标签符号高度敏感,简单的标签替换可能导致性能大幅波动,反映训练数据中的语言偏见及表征局限。
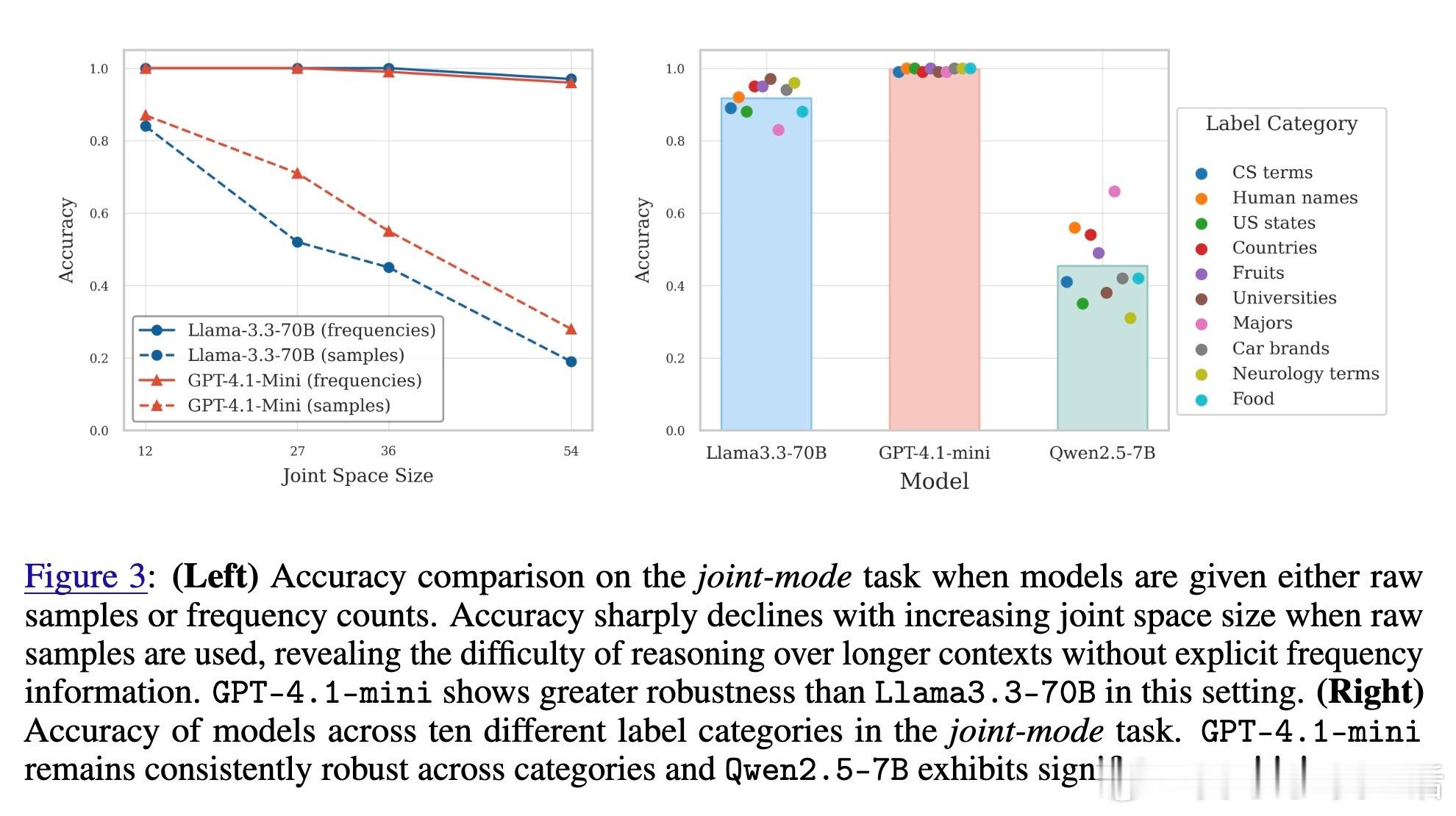
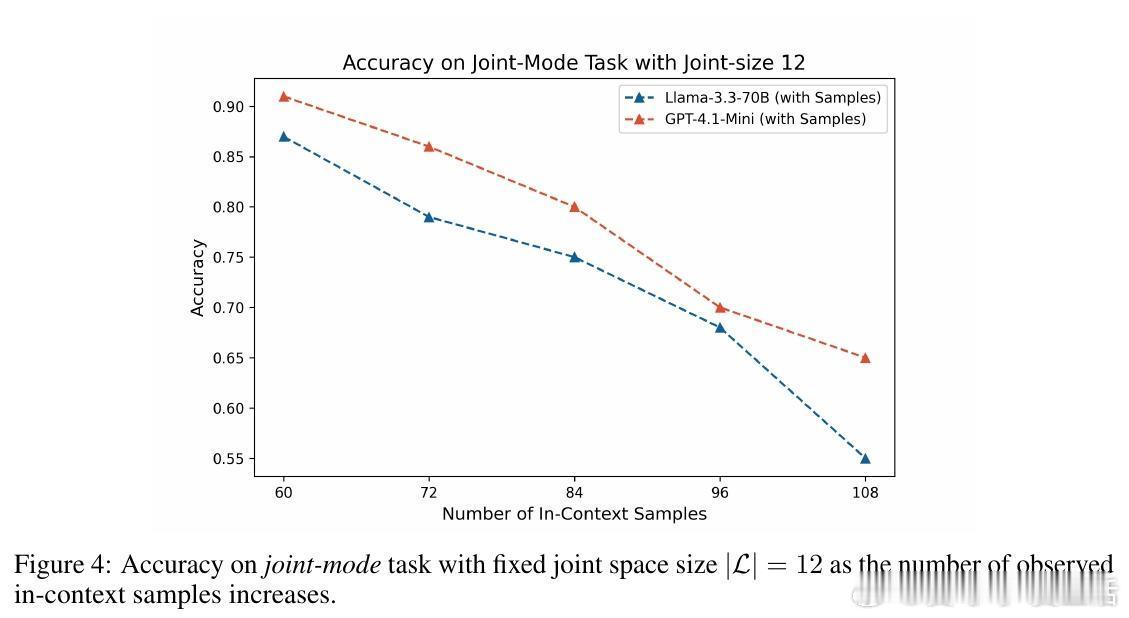
• 当输入为原始样本而非频率统计时,模型表现急剧下滑,尤其在长上下文中计数能力不足,限制了其对大规模数据的推理。
• 通过引入代码解释器辅助计数,GPT-4.1-mini显著恢复了性能,表明问题关键在于模型对长序列的计数和记忆能力,而非推理本身。
• 样本独立性分析显示生成的样本存在自相关,说明LLMs的采样仍受上下文影响,尚未实现真正的随机独立抽样。
心得:
1. 规模与蒸馏显著提升了概率推理能力,表明模型容量和训练策略是关键变量。
2. 条件推断复杂性揭示了推理链条中更深层次的信息处理需求,提示未来应加强条件概率建模。
3. 计数和上下文管理是当前LLMs的瓶颈,结合外部计算工具或混合推理框架或为突破口。
详情阅读🔗arxiv.org/abs/2509.10739
人工智能大语言模型概率推理机器学习自然语言处理