两年前差点以50亿美元卖给英特尔的TowerSemiconductor,在短短几个月内股价翻了一倍多,创下20年新高。如下图所示,2025年8月,Tower的股价还在50美元上下缓慢移动,而到11月12日Tower的股价一路飙升至106.42美元。对于一家成熟半导体厂商而言,这样的速度几乎闻所未闻(英伟达除外),市场情绪之高涨可见一斑。更重要的是,回顾2005—2025这二十年,Tower的估值长期处于较低的水平,此次爆发就在行业中格外醒目。
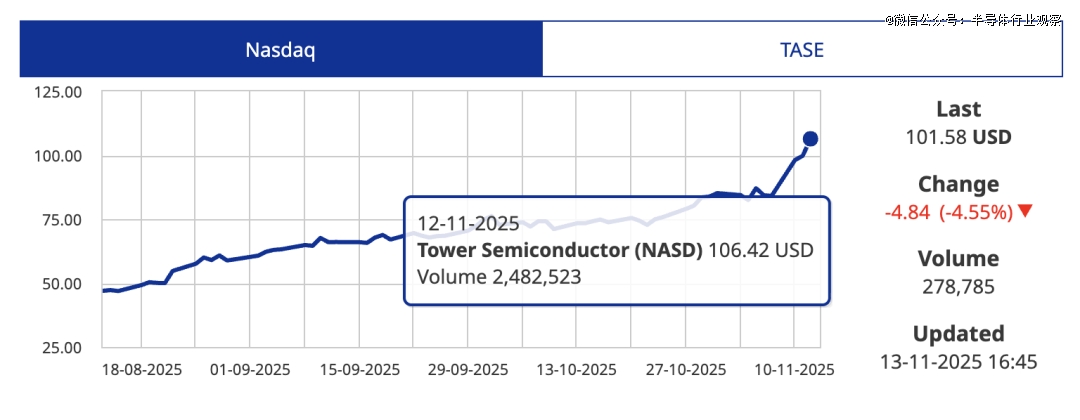
图注:Tower从25年8月~11月的股价走势
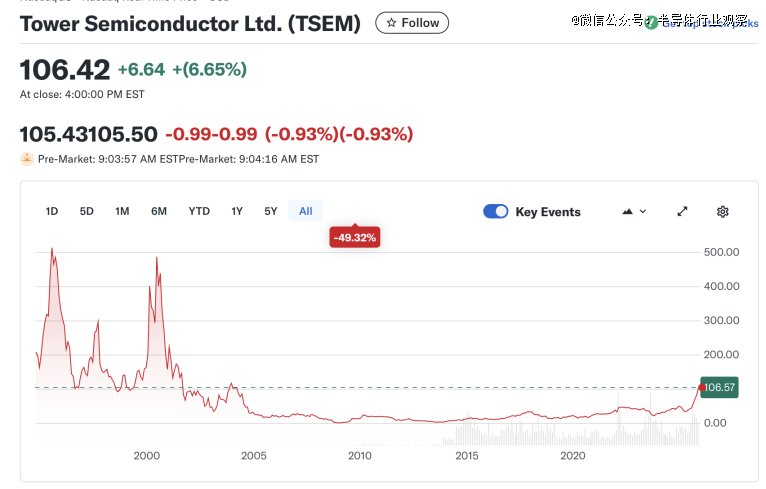
图注:从1994年底~现在,Tower的股价情况
看似是一桩资本故事,实则揭开了一个更大的趋势:当AI带来的算力需求全面爆发,硅光互连背后的高价值正在被体现出来。
为何硅光是*答案?
在AI之前,互连不是行业焦点。CPU带宽、服务器拓扑、数据交换规模都还在可控范围内,铜线足够、PCB足够、材料也能够撑住。
但当算力架构从单机演进到大规模GPU集群、从数十个GPU扩展到数万甚至百万节点连接后,互连体系成为整个系统的*瓶颈。一旦进入GPU并行、千卡训练、百Tb/sFabric网络的时代,一切参数都呈指数级膨胀:一个10万GPU的集群可能需要50万条互连链路,承载这些链路的设备包含成千上万台服务器与交换机,如果规模扩展到100万GPU,互连数量可能突破1,000万条,仅网络部分的能耗,就可能逼近1吉瓦(GW)级别。换句话说,算力规模越大,网络成本、功耗和物理连接复杂度呈指数级增长,而不是线性增长。这也是为什么,互连技术在AI时代从幕后走向前台。
过去,服务器—服务器、GPU—GPU之间主要依赖铜缆互连。然而,当单通道速率从56G→112G→224GPAM4不断提升后,纯铜方案开始遭遇不可回避的物理极限:
可达距离急剧缩短:频率翻倍,通道损耗指数式增加,板内/背板/线缆都很吃力;重度均衡会带来功耗和延迟上升。
带宽密度受限:想要更大总带宽,就得更多走线/更厚背板/更复杂连接器,PCB面积和材料成本飙升。
EMI/完整性难题:串扰、辐射、反射等SI/PI问题让“再堆料”越来越不可持续。
于是,行业开始意识到:高速互连,必须从电,走向光。
然而,传统光模块上位后,很快就遇见成长性瓶颈。传统光模块诞生于“电信级光通信时代”,目标是传很远(几十到几千公里)、传很稳、单价高但量不大。光通信大多发生在机房和机房之间,城市与城市之间。其特点是:器件多为分立元件,光学器件靠拼装,成本结构偏重人工、封装、光学对准,激光器多采用EML(电吸收调制激光器),贵且产能有限。这种架构在“城际长距通信”很好用,但到了AI数据中心,问题就出现了。
AI时代,光通信大量发生在服务器与服务器之间、GPU与GPU之间,甚至未来会发生在芯片封装内部(CPO)。也就是说,光从“远距离传输”变成了“近距离高密度互连”。这对光模块提出了全新要求:更大带宽(400G→800G→1.6T→3.2T)、更低功耗、更小体积和更低成本(AI服务器数量太多)。
传统的光模块难以同时满足这四个方向,且有三大主要瓶颈:*,从成本上来看,传统光模块成本40–60%来自:激光器、封装对准和光学组件制造,其中EML激光器是标配,但制造难、成本高、产能有限;第二,从功耗上来看,速率越高,驱动越吃力。200G/lane(1.6T)时代,传统模块功耗难以压低。而数据中心能耗受限,PUE/POD预算非常紧张;第三就是器件多、组装复杂、难以规模化。1台AI服务器可能需要数十个800G/1.6T光口,从量上讲,传统模块体系根本供应不过来。
于是,硅光开始登上历史舞台。其实硅光并不是新概念,但AI属实给了它*次“产业级落地窗口”。硅光是一种利用CMOS工艺制造光通信所需的数百种元器件的技术,多年来一直被用于生产城域网和长距离通信的相干光模块。
与传统光模块不同,硅光子采用常见的波长(CW)激光器,成本更低、制造更容易。Marvell云光学执行副总裁兼总经理LoiNguyen表示:“CW激光器就像一个灯泡……它只是发出一束恒定的光。它更容易制造,可以从多个来源获得,而且价格便宜。所有用于调制数据的高速‘魔力’都发生在硅光芯片内部。”硅光子器件还可以在200mm和300mm的晶圆厂中生产。

图注:硅光模块的内部组成结构
(图源:Marvell)
为什么硅光在此刻变得关键?Marvell举了一个例子:如果一个分立模块在一个芯片中有八个200G通道,它需要四个EML激光器才能来驱动1.6T的总速率。而使用硅光,所有功能都被集成,4个通道可以共享1颗激光器,因此,整个1.6T模块只需要2颗价格更低、制造更容易的CW激光器。不仅如此,集成硅光子模块可靠性更高,更易于规模扩展,供应链压力更小,成本结构更优。

因此,技术趋势非常明确:铜互连的物理瓶颈+传统光模块的结构性限制=硅光走向必然性。硅光将是下一代算力基础设施。
硅光互联,三步走
从外到内,行业在经历硅光演变“三步走”的进化:
*步:线缆级有源化(AOC/AEC)。最初,行业通过在电缆端加入放大与均衡电路,让信号在铜介质中“多跑一点路”。这种有源化线缆延长了电互连的寿命——在电域信号质量衰减前先把它整理干净,相当于为传统铜线续命。
第二步:可插拔光模块(LPO,QSFP-DD/OSFP/OSFP-XD等)。当速率提升到400G、800G乃至1.6T,电缆再难支撑带宽与距离。于是行业转向在机架内、机柜间大量采用短距光模块,在交换机与加速器端口直接完成“电-光转换”,例如线性直驱/低DSP(LPO),在可插拔时代用“更轻”的均衡链路,牺牲一点链路容差,换更低功耗和更低时延。这一步让光通信开始进入数据中心内部,成为目前高带宽互连的主力形态。
2024年6月,Marvell展示了一款6.4T3D硅光引擎实机演示:该引擎内置32条通道,每条均可实现200G电/光传输速率。这一新架构将数百个光通信功能集成进芯片之中,包括将TIA与驱动器集成到同一器件上。作为业内*具备这种集成方式的产品,它采用模块化设计,可实现从1.6T扩展到6.4T甚至更高的带宽等级。最开始的方式就是可插拔式光模块,其通道数量将从现有的单模块8通道扩展到16、32甚至64通道。
第三步:封装级光学融合(CPO/NPO/OBO)。进一步的趋势,是把光引擎搬到芯片封装边缘甚至同一封装内。电走线缩到最短,功耗、延迟和热罚显著下降。再往前,则是硅光子SoP(SystemonPackage)/SiPho共封方案——这可能是AI光互连的*模式,让光、电在同一片硅上自然耦合,实现真正意义上的“光计算一体化”。
从演进路径来看,短期可插拔仍是主流(灵活、可维护),中期线性直驱/低DSP降低PUE,中长期CPO/近封装光学在大型训练/交换平台落地,进一步把“光”推进到芯片边缘。
这对产业链来说意味着什么呢?
从需求面来看,光模块从以前的“长距少量高价”转为“短距大量高密度”。量级的扩大,直接驱动光模块出货与光器件/工艺产能双增长。光模块从“少量配置、长距离应用”转向“每台服务器、每个板卡、每个芯片都可能需要配备”的标配。
从供给面来看,芯片厂商、代工巨头、互连厂商纷纷开始布局硅光技术。例如,2025年11月,Tower宣布新的CPO(co-packagedoptics)代工服务平台,兼容其SiPho/SiGePDK,并引入300mm晶圆键合、3DIC多技术叠层设计流。
沾硅光,就涨
根据LightCounting的数据,全球光互连市场自2020年以来已翻了一番,到2025年将接近200亿美元,预计到2030年将再次翻番,行业复合年增长率(CAGR)约为18%。更有意思的是,如果将视角收窄至人工智能数据中心场景,增长曲线会变得更陡峭。LightCounting预计,到2026年用于AI集群的光模块、LPO和CPO市场规模将突破100亿美元,相比2024年翻倍增长。并且随着大模型训练规模扩大、CPO进入部署期、硅光加速进入主流封装形态,该市场在2030年将进一步达到200亿美元规模。
资本市场早已嗅到这种“结构性供需反转”的气味。从AI算力到光互连的传导链条如下:AI模型增长→GPU集群爆发→内部互连升级→光模块需求倍增→硅光/SiGe产能紧俏。于是但凡沾硅光的产业链条上的每个环节都在吃AI的红利:
代工厂:代表性厂商Tower
在最新的季度财报上,Tower强调了硅光在其业务营收中的核心地位。2025年第三季度,Tower的营收为3.96亿美元,环比增长6%。公司预计2025年第四季度营收为4.4亿美元,上下浮动范围为5%,反映出营收同比增长14%,环比增长11%。TowerSemiconductor首席执行官RussellEllwanger表示:“我们在光模块所需的硅锗(SiGe)与硅光(SiPho)技术领域处于行业*地位,再叠加数据中心需求的强劲上升,使Tower在收入与利润两端都具备前所未有的增长潜力。”
Tower市值实现翻倍,其核心原因就是硅光领域产能需求旺盛、市场需求大幅增长。在光模块关键工艺环节,Tower在硅光工艺与先进SiGe工艺(用于TIA制造)领域具备全球*实力,技术优势显著。其中,可满足单波200G性能需求,FT截止频率覆盖300~400GHz,为高性能光模块量产提供核心支撑。
其实除了硅光,先进节点DSP、跨阻放大器所需的先进硅锗(SiliconGermanium)工艺等,也都是核心支撑技术。高速光模块中的光电探测、驱动放大、跨阻放大(TIA)等,是光模块性能瓶颈之一。SiGe工艺由于其高频、高增益、高线性特点,成为驱动这一类器件的*。SiGe工艺能提供高达300~400GHz的截止频率,是高速光链路的关键放大技术。Tower也指出,硅锗技术搭配硅光子是其未来增长路径。

图注:Tower能够提供硅光代工的晶圆厂
(图源:Tower)
对此,Tower正在加大马力扩产。“我们正在推进客户认证,同时继续加大对NewportBeachFab3的投资,并对另外三座晶圆厂进行重新规划与追加投资,以支撑全新的丰富的SiPho与SiGe产品组合。新增产能的初步释放,已经体现在我们第四季度创纪录的4.4亿美元营收指引中。”Ellwanger进一步指出。
激光器:Coherent
前文我们谈到了光模块中激光器的重要作用,Coherent就是激光器领域的重磅玩家,属于芯片产业链中的“掐喉位”。Coherent是全球*的EEL/EML激光器、DFB/DBR光源、CW激光光源(适配硅光模块)。此外,随着CPO、LPO、光背板(OpticalPCB)、2.5D/3D光电封装、Chiplet光互连等逐渐进入实装阶段,Coherent所能提供的VCSEL阵列、光纤阵列和光耦合方案变得重要。也就是说,硅光规模化越快,Coherent越受益。可以看到,2025年Coherent的股价也出现了陡升。
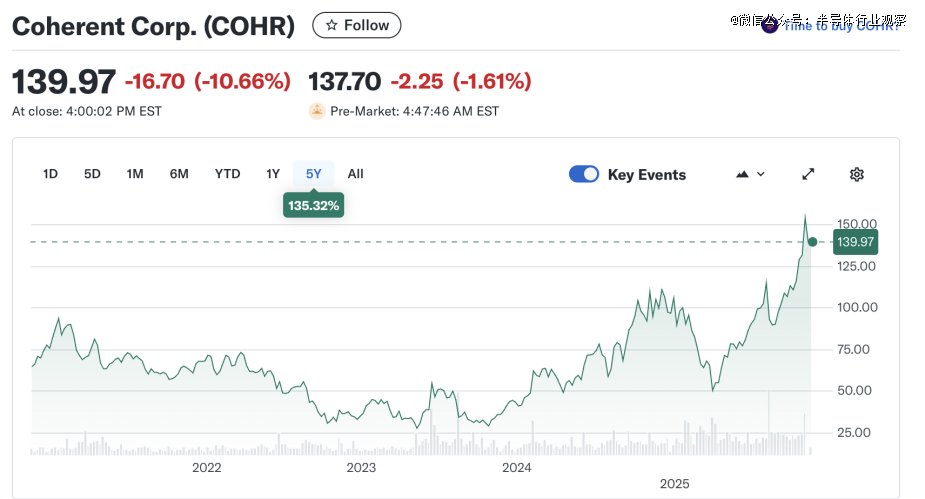
图注:Coherent股价情况
Coherent刚刚发布了截止2025年9月30日的2026财年*季度的财务业绩,*季度营收为15.8亿美元,同比增长17%。其中公司当前增长几乎全部来自AI相关数据中心需求,同比增长26%。目前Coherent的业务结构中69%来自数据中心与通信,剩下31%来自工业业务。公司还推出了400mWCW激光器,用于CPO与硅光子设计。
光模块:进入2025年下半年以来,中际旭创、新易盛、天孚通信等企业的股价出现明显加速上涨,几乎同步完成估值再定价:
中际旭创股价突破500元,总市值超过5,000亿元;新易盛股价突破430元,总市值迈入3,000亿元区间;天孚通信股价触及224元,市值升至1,200亿元以上。这些企业在2025年前三季度收入与利润全面增长,其中800G光模块已进入加速放量阶段,而1.6T光模块正在进入量产前夜。
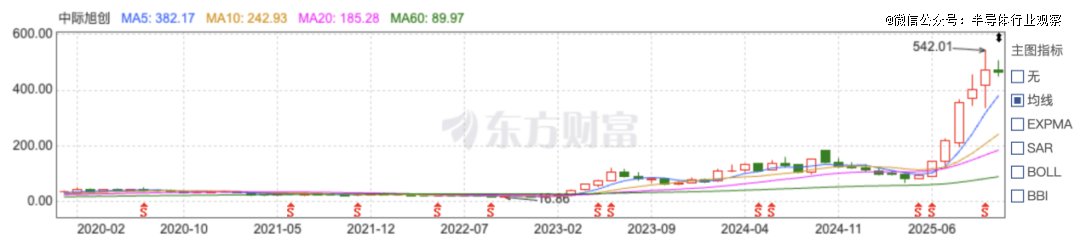
图注:中际旭创股价走势
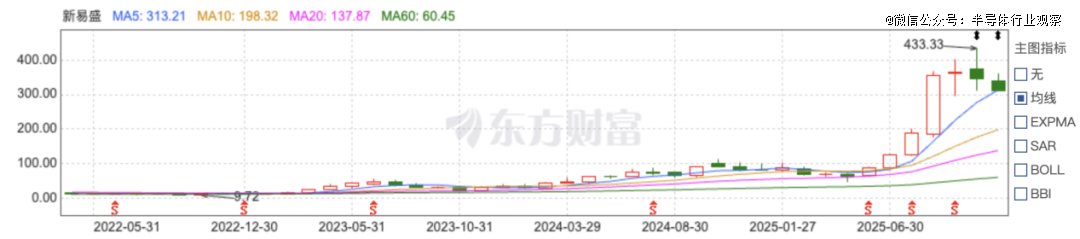
图注:新易盛股价走势
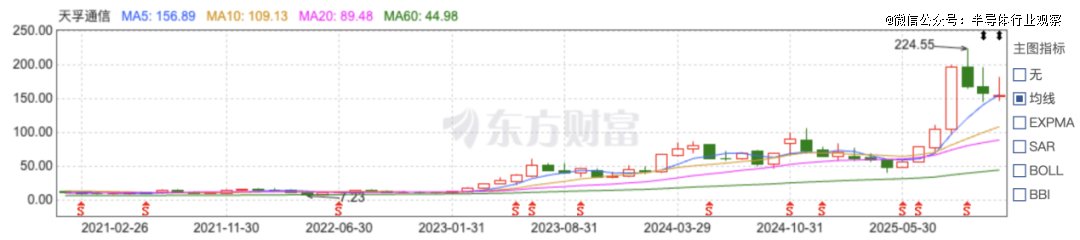
图注:天孚通信股价走势
硅光互连系统层玩家:博通、Marvell、NVIDIA等巨头。
硅光互连行业能走到今天这一步,很大程度上是因为博通和Marvell这两家公司在技术路线、芯片标准、生态推动与系统部署层面做了关键推动。
在AI数据中心里,绝大多数交换机都围绕Broadcom的两大旗舰路线构建:Tomahawk系列,用于HyperscaleAI数据中心Fabric枢纽;Bailly(CPO)系列,是下一代1.6T/3.2T级别硅光共封装方案。Broadcom的强势来自三点:掌握交换芯片、拥有高速SerDes/PHY/DSP技术(硅光必需)、不断推动LPO与CPO双路线。
如果Broadcom是“标准制定者”,那么Marvell就是硅光真正走向量产和落地的工程执行者。Marvell是全球*的DSP供应商之一(原Inphi的技术),CPO/LPO光引擎技术*。前文我们谈到了Marvell最新展示的6.4T硅光引擎能够实现从1.6T→6.4T模块化扩展。
下图展示了一套采用SENKOAdvancedComponents与Marvell技术打造的概念级CPO(光电共封装)AI计算托盘。这个1U托盘可容纳4颗XPU(CPU/GPU/NPU/DPU等计算芯片),并通过1024芯光纤提供高达102.4Tbps的互连带宽。每颗XPU都连接着四颗Marvell的6.4T光引擎,用于完成电–光信号转换。这些光引擎通过两枚SENKO提供的可拆卸式36芯金属光芯片耦合器(MPC)与系统光纤连接。这种由CPO支持的互连密度与传输距离,远远超出了铜互连所能达到的物理上限。
英伟达一手握着GPU算力核心武器,另一手也是配套性的“搞基建”。今年3月份,英伟达推出了集成硅光子技术的共封装光模块(CPO)交换机。其CPO将可插拔收发器替换为与ASIC封装在同一芯片上的硅光子技术,与传统网络相比,可实现3.5倍更高的电源效率、10倍更高的网络弹性以及1.3倍更快的部署速度。
下面就让我们透过英伟达这个CPO交换机详细了解一下硅光是如何实现的:

图注:英伟达的Quantum-XPhotonics封装平台

图注:CPO芯片的光互连结构:324条光互连通道,36路激光输入,288条数据链路,内置光纤管理结构

图注:这是一个可拆卸的光学子模块,内置3个硅光引擎,具有4.8Tb/s数据吞吐能力

图注:这是整个系统里最关键的一块——硅光引擎。它使用200Gb/s微环调制器,单颗引擎就能实现1.6Tb/s的吞吐能力,并且功耗比传统互连方式降低3.5倍。

图注:这里展示的是硅光引擎的内部结构。上方是光纤阵列连接器,用来把数十甚至数百条光通道精确对准芯片。中间结构是关键,它把电子芯片和光子芯片通过3D堆叠方式融合在一起,实现高速调制和信号处理。底部是封装基板,用来提供供电、散热和机械稳定性。

图注:硅光引擎的芯片采用台积电N6(6nm)节点集成约2.2亿个晶体管,芯片中包含超过1000个光子学组件,体现了电子–光子深度混合集成的制造水平

图注:该图展示了一个完整硅光引擎内部的三层结构逻辑:上层是光学器件:波导、调制器和探测器;中间是耦合层,让光从光纤阵列进入芯片;底部是基于台积电6nm工艺制造的电子逻辑层,内含2.2亿个晶体管。

图注:图中展示的是多平面光互连接口,共使用1152根单模光纤,实现高密度、多通道的数据传输,是CPO系统从芯片内部光信号通向系统级网络的关键结构。

图注:硅光系统中最重要的器件之一——外置激光源ELS。单个ELS集成了8颗激光器,它向多个硅光引擎提供持续、稳定的光源。ELS的好处包括:大幅降低成本(减少激光器数量)、减少热源、提升可靠性、统一供光,易于功率管理、模块可拔插、易维护、更容易规模化。这就是为什么硅光能够真正走入数据中心。

图注:这是一台完整的光互连系统。它内部拥有4460亿个晶体管,搭载18个外置激光源,通过144根MPO光纤与外部系统连接,总带宽能力高达115Tb/s。
为什么说硅光不是短期泡沫?
短期来看,这一轮硅光概念的爆发,确实有明显的资本情绪推动特征:股价短时间翻倍、新闻密集曝光、产业链公司估值快速扩张——这与任何“技术拐点+AI叙事”模式高度一致。但硅光不是一个靠嘴巴炒热的故事,而是一个被算力需求倒逼、无法绕开的产业趋势。
为什么说硅光不是短期泡沫?从三个维度看:供给端限制、需求端确定性、技术路径不可逆。算力越堆越多,硅光需求越强——这不是周期,而是新范式。
再者,判断硅光是否泡沫,可以看两件事:有没有标准?有没有量产?这两个问题的答案现在是:都在发生,而且速度很快。Marvell发布6.4T硅光引擎;NVIDIA推出CPO交换机;Broadcom推进Bailly硅光架构;Tower、GlobalFoundries、TSMC建立成熟硅光工艺平台;Meta、Microsoft、OpenAI、AWS大规模建光互连数据中心;新易盛表示以目前看到的客户端产品需求及订单情况,预计在明年硅光产品占比是明显提升趋势;中际旭创投资者问中显示,2026年大客户需求指引明确,预计2027年,1.6T更大规模上量、Scale-up的光连接方案和全光交换机方案等产业趋势也将逐步显现。。。。
硅光产业链一旦规模化,赢家会形成极强马太效应——不是均匀分蛋糕,而是赢家通吃。而目前:高端DSP只有2家,CPO架构实际落地厂商