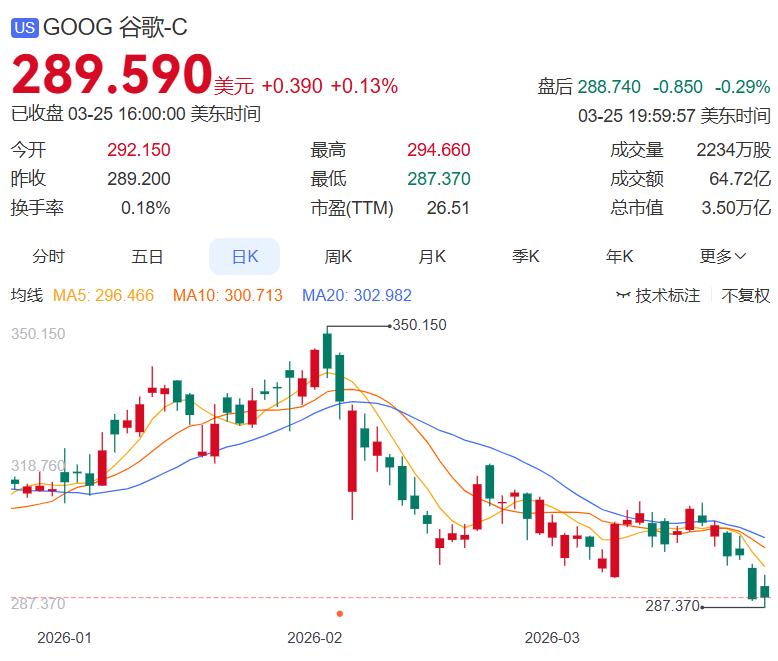
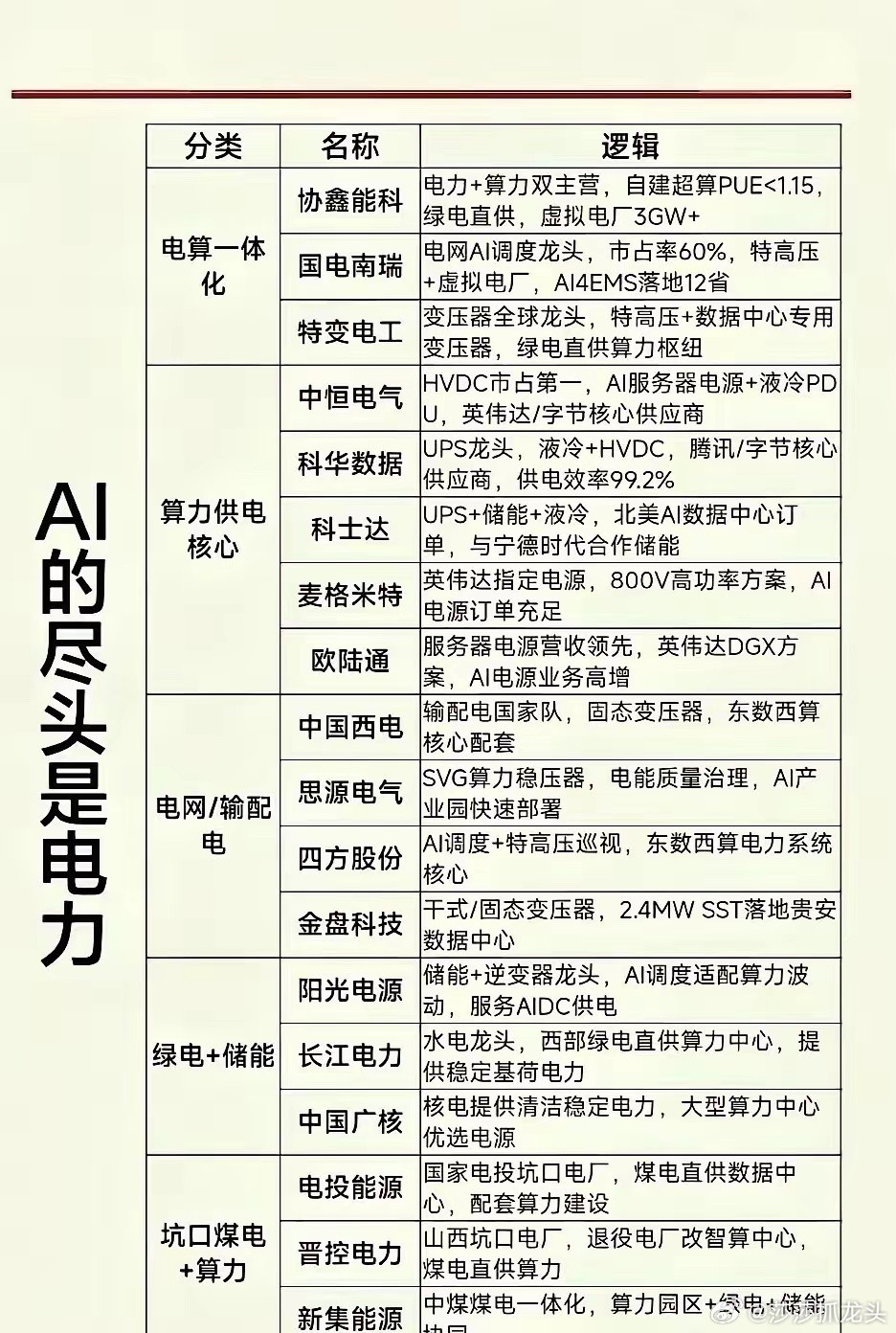
人工智能确实是未来的趋势,每一次技术革新都是在给未来铺路 谷歌扔出一颗"算力炸弹"——TurboQuant压缩算法,直接把AI内存需求砍掉6倍! 这项技术专攻大语言模型最头疼的键值缓存(KV Cache)瓶颈,能在不重新训练模型的前提下,把缓存精度压缩到3bit,同时几乎不影响准确率。测试结果显示:在英伟达H100上最高实现8倍性能提升,Gemma、Mistral等开源模型都能直接套用。这意味着什么?同样的硬件,能跑的上下文窗口直接翻几倍,或者成本腰斩——这对整个AI产业都是降维打击。 但更值得关注的是,TurboQuant瞄准的是"推理环节"而非训练。现在大模型竞争已经从"谁能训出大模型"转向"谁能低成本跑推理"。KV Cache正是推理时的内存大户,上下文越长、并发越高,内存越爆。谷歌这招相当于给推理引擎加了涡轮增压——不换硬件、不改模型,就能多塞几倍的请求。说白了,这是把AI应用的边际成本往下砸了一个台阶,对ToB和ToC的应用落地都是实质性利好。 技术细节里还藏着一条暗线:TurboQuant计划在4月的ICLR 2026上正式亮相,但更关键的是,这项技术还能用在向量搜索引擎上。 这意味着它不只是服务大模型,还能提升所有需要向量检索的系统效率。目前业界同类技术(如KVQuant、KIVI)大多停留在学术阶段,而谷歌直接甩出工程化方案,并且已经在H100上跑通了。当别人还在卷算力时,谷歌已经开始卷"算力利用率"了。这或许比Scaling Law更值得期待。