向量数据库的核心任务是对文本或其他非结构化数据生成的 Embedding 做相似性搜索。时间戳、文档类型、所有权一类的上下文约束,一般以外部过滤器的形式在向量搜索前后进行。多数场景下这一架构运作正常,但当上下文信号需要参与排序就会有问题。本文分析传统向量数据库架构的过滤与检索机制,并介绍 Aspected 的 Aspect Database:一个面向 AI 系统的上下文感知检索引擎,将上下文属性经由多 Aspect Embedding 直接编码进相似性计算所用的表示中。
向量搜索中的上下文挑战向量数据库已经AI 系统的基础设施层。语义搜索、检索增强生成(RAG)、推荐系统、相似性检测,都依赖它来完成核心检索环节。文档以向量 Embedding 的形式存储,检索则在这些 Embedding 上执行近似最近邻(ANN)搜索。
但现实中的检索几乎不会只看语义相似性。系统往往需要处理带有上下文约束的查询:来自特定部门的相似文件、某个时间区间内与某概念相关的文档、具有特定密级或分类级别的文档。
传统搜索引擎用结合了结构化条件和文本相关性的查询语言来解决这类问题。到了向量搜索体系中,上下文约束与相似性搜索的整合就没那么直接了。
向量检索中从过滤器到特征的转变多数向量数据库把上下文属性当作过滤器,而非相似性计算的组成部分。相似性搜索负责度量语义距离,过滤器负责按元数据裁剪候选集,二者各行其道。另一种思路是把上下文信号纳入相似性空间本身,让它们直接参与 ANN 搜索的向量距离计算,而不是在搜索结束后才发挥作用。
Aspect Database 正是基于这一思路构建的检索引擎,文档不再只有一个文本派生的 Embedding,而是通过多个向量化的 Aspect(即上下文属性)来表示,相似性搜索可在内容维度与上下文维度上一并进行。
传统向量数据库如何处理过滤器FAISS、Pinecone、Redis 等主流向量数据库系统大体遵循一套通用检索模式 。典型的查询流水线包含三步:生成查询 Embedding、在向量索引上执行最近邻搜索、通过过滤器施加上下文约束。过滤在流水线中的切入位置因实现而异。
前置过滤在相似性搜索执行之前缩小搜索空间,移除不满足条件的文档。空间确实缩小了,但当上下文信息不完整或含有噪声时,相关文档也可能一并被排除。后置过滤在评分完成之后移除不合条件的结果,不会过早丢弃候选项,代价是需要拉取更大的候选集来保证最终有足够的有效结果。
生产系统经常把两种策略混合使用,再叠加重排序模型或应用层逻辑。混合方案在很多场景下表现良好;但当上下文属性不只是用来限制结果、而是应该直接影响排序时,额外的复杂性就难以回避。相似性计算与上下文过滤之间的架构割裂带来了一系列工程层面的约束,也往往催生出需要精细调优和编排的多阶段检索流水线。
基于过滤器架构的工程局限性上下文属性一旦被纯粹当作过滤器,就无法对相似性分数产生任何影响。如果上下文信号代表的是相关性的梯度而非刚性的准入条件,问题就很突出了。
以下面的查询为例:
查找与金融风险相关的近期内部合规报告。
在典型的向量数据库架构下,处理这条查询一般需要三步:
对文档 Embedding 执行向量相似性搜索,获取与金融风险相关的报告。
用元数据过滤器或时间范围把结果限定为近期文档。
可选地再做一次重排序,将更近期的报告前置。
实际开发中,工程师通常会引入多次查询、自定义打分逻辑或重排序阶段来弥补上述不足。手段有效,但架构复杂度和应用层的编排工作量也随之上升。
根源在于结构层面:上下文信号是在相似性空间之外处理的,搜索阶段本身不感知它们。所以就出现了新的方式,把上下文属性直接编码到相似性模型中。
Aspected:多 Aspect 检索Aspected 跳出了单一 Embedding 的框架。在 Aspect Database 中,每篇文档由多个向量化的 Aspect 来表示——语义内容、时间属性、媒体内容等——每一种都对应一个独立的向量化维度。传统向量检索在度量语义距离上表现不错,但对于实际检索中影响相关性的上下文信号,它很难兼顾。
这套方案不把上下文属性存到旁路字段再做过滤,而是将其编码为向量表示,直接拼入文档的整体向量表达中。搜索时使用的是整合后的表示,每个 Aspect 都在排序计算中贡献权重。
站在向量数据库的视角看,搜索操作本身没有变化,变化的是"相似性"所承载的含义。相似性不再只反映语义上的接近,而是一个涵盖文档多个 Aspect 的复合度量。Aspect Database 据此可以在一次搜索中找到既语义相关、又在上下文维度上对齐的文档。
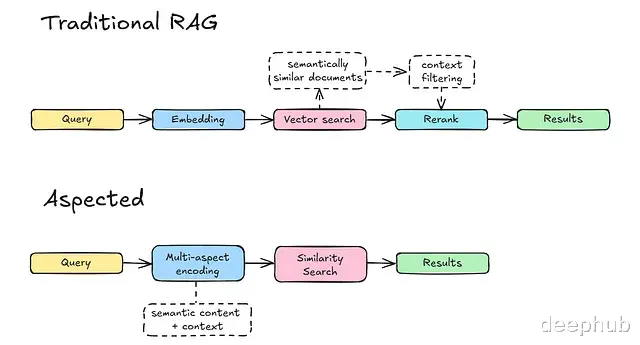
基于过滤器的检索与多 Aspect 检索的对比
实际示例:内容和时间继续前面的场景。一个系统中存储了大量合规与监管报告,分析师想检索的内容是:
近期讨论金融风险的报告。
传统向量检索架构处理这类查询,需要把语义相似性搜索与额外的过滤或排序逻辑结合起来,才能兼顾时间约束。
Aspected 的处理方式不同:时间属性与语义内容一道编码进文档表示。检索过程简化为三步:
跨相关 Aspect(内容和时间)生成查询表示。
对多 Aspect 表示执行相似性搜索,搜索策略可以在距离计算中选择性地纳入或排除特定维度,灵活度高于标准 ANN 方法。
返回按多个 Aspect 的组合相似性排序的结果。
时间属性直接参与相似性计算后,主题相关性和时间接近度在同一次搜索中完成评估,不再需要额外的过滤或重排序阶段,返回的结果也更贴合实际的相关性预期。
过滤器仍然适用的场景当上下文属性表达的是刚性约束——安全边界、租户隔离、访问权限、文档类型限制——过滤器依然是正确的选择。它界定的是准入资格,不是相关性。
但企业检索场景中还存在大量"灰度"上下文信号:领域接近度、组织归属、监管背景。它们影响的是结果的相关程度,而非结果是否应该出现在列表中。将这类信号纳入相似性计算,比用过滤器处理更准确也更省钱。
总结AI 应用对向量搜索的依赖在持续加深,检索架构也在向语义距离之外的方向演进。上下文属性、结构信号、领域特征,都在影响着一篇文档在具体检索场景中是否算"相关"。难点不止在于提取这些信号,更在于把它们编入相似性模型本身。
Aspect Database 是对这一方向的一次落地实现——在它构建的向量搜索系统中,内容与上下文共同参与相关性计算。
论文:
https://avoid.overfit.cn/post/b7adbcf46072453d96dade711e1be514
by Aspected