新智元报道
[新智元导读]AI终极挑战——物理图灵测试。这一年,英伟达JimFan领导的GEAR实验室,正用一套完整的技术栈,向这堵高墙发起总攻。
机器人「物理图灵测试」距离真正通关,还需一段时间。
英文达杰出科学家JimFan表示,我正全身心投入一个单一使命:为机器人解决「PhysicalTuringTest」(物理图灵测试)。
这是AI的下一个挑战,甚至可能是「终极挑战」。

如今,人类光靠文本字符串实现的超级智能,恐怕就已经能拿到诺贝尔奖了。
不过机器人现在,连黑猩猩级灵活度、操作能力都还没有。
「莫拉维克悖论」(Moravec'sparadox)是一种必须被打破的诅咒,是一堵必须被撕碎的高墙。
没有任何东西,应该阻挡人类在这个星球上实现指数级的物理生产力,甚至有朝一日,把这种能力带到其他星球。
这一年,JimFan带队在英伟达创立了GEAR实验室,30人团队已初具规模。
令人震撼的是,团队的产出和影响力,远远超过它的规模。
从基础模型、世界模型、具身推理、仿真、全身控制,以及各种形态RL,几乎囊括了机器人学习的完整技术栈。

接下来,一起看看GEAR2025年。
GR00T基础模型,一年三代
GR00T是英伟达提出的「通用机器人基础模型体系」,核心目标——
让机器人像「大模型」一样,具备跨任务、跨场景、可迁移、可学习的能力。
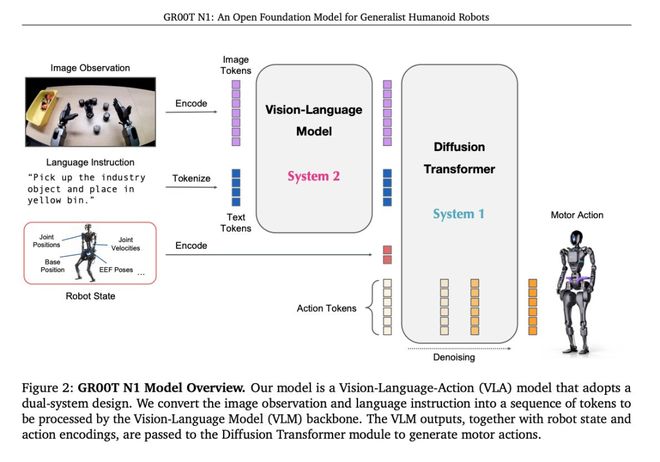
GR00TVLA基础模型,是最具代表性的成果之一。
它将视觉+语言+动作三种模态,统一到一个端到端的模型中,让机器人能够看懂环境、理解人类指令,生成可转型的连续动作。
这一年,英伟达对GR00TVLA进行了高频迭代:
今年3月开源了N1,紧接着6月发布了N1.5,12月又推出了N1.6。
GR00TN1
3月,GR00TN1开源首发,仅用20亿参数,即可验证VLA架构在真实机器人任务中的可行性。

它的开源,为整个机器人生态系统提供了一个前沿的基础模型。

GROOTN1可以轻松在上见任务中进行泛化,或执行需要长上下文和多种通用技能组合的多步骤任务。
比如,抓取、用一只手臂/两只手臂移动物体,以及在两个手臂之间传递物品。
GR00TN1.5
GR00TN1.5是N1的升级版,在架构、数据、建模层面进行了多重优化。
它使用了更领先的视觉语言模型——EagleVLM,提升了语言理解和视觉感知力。
还加了FLARE损失,提高了对未来动作预测的一致性。
在仿真机器人基准任务中,GR00TN1.5成功率明显由于上一代模型。

GR00TN1.6
这个月迭代后的GR00TN1.6,集成了更强的架构和推理能力,让机器人在复杂环境中表现更智能、更稳健。

GR00TDreams:机器人「做梦」学习
视频世界模型,是数据驱动的物理和图形引擎。
DreamGen,是一种利用AI视频世界模型,来生成合成训练数据的机器人学习框架。

它通过「数字梦境」生成大量虚拟机器人行为,再从视频中提取动作数据,用于训练机器人策略,从而实现新任务和新环境中的泛化学习。
实验验证了,机器人从只有一个动作示例的场景中,通过「梦境」生成数据,在新任务上有很高的成功率。
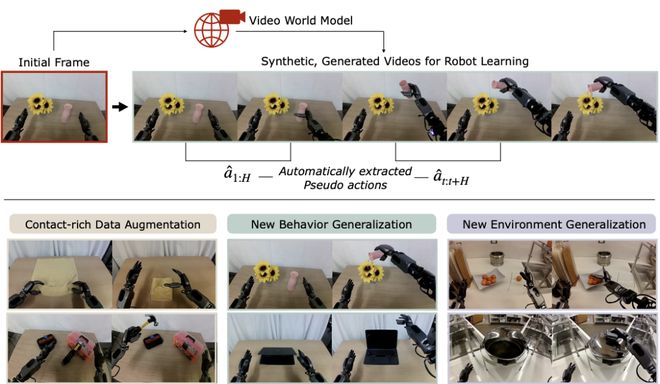
在10个新环境+22种新行为上,机器人都能泛化成功。
SONIC:让机器人具备「通用运动能力」
为了让机器人不仅只会做某个动作,而具备几乎所有人类可以做的动作。
英伟达团队提出的SONIC,一个用于人形机器人控制的通用运动系统。
它的核心目标是,让人形机器人像「角色」一样被控制、学习和驱动。
SONIC出发点很明确,运动追踪是人形机器人可扩展基础任务。
只要机器人能够稳定、准确跟踪任意人类动作,那么行走、转身、抬手、抓取、协调全身运动等复杂行为,都可以统一到同一个框架中。
论文中,团队将运动追踪任务进行了「超大规模化」(Supersize),即9000+GPU小时,以及超1亿动作帧,覆盖了机器丰富的人体动作分布。
这让SONIC学会了人类运行的整体结构,而且,研究人员还基于SONIC构建了多种控制与交互方式。

SONIC的探索,为通用人形机器人提供了一个可扩展、可编程、可落地的运动基础系统。
其他重磅成果
除了以上一些重磅成果,团队还在面向VLA强化学习后训练上,以及sim2real的RL实践做出了探索。
比如PLD(Probe,Learn,Distill),让机器人从失败中「自我进化」。
它是一套真实世界「自举式学习」的训练范式。
一般来说,机器人在真实环境中,执行高精度操作任务时,或失败、会偏移,都成为了一种信号。
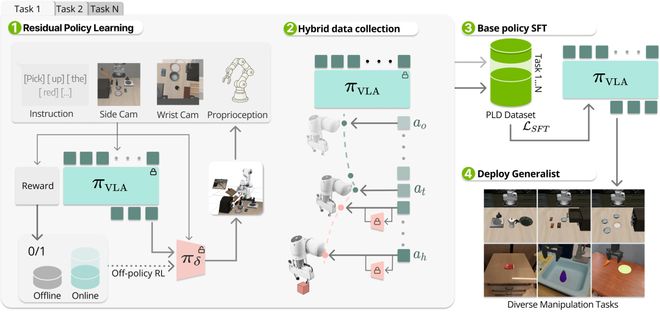
PLD引入了真实世界残差强化学习(ResidualReinforcementLearning),不推翻原有策略,而在已学会动作基础上,学习「微调残差」,专门负责纠错、恢复、补偿。
最后,它将真实世界中学到的改进经验,蒸馏回VLA主模型,使用SFT,将临场学到的技巧变成长期能力。
对此,JimFan表示RL能够通过后训练VLA模型,在高精度任务(如GPU插入)中实现接近100%的鲁棒性。
这是解决工业部署「最后一公里」难题的关键进展。

VIRAL(VisualSim-to-RealatScale)是一套纯视觉人形机器人Sim-to-Real框架,为了解决一个长期难题——
让机器人在真实世界中,零样本完成「走+站+操作」连续长时任务。
研究在UnitreeG1人形机器人上,验证了最长54次连续loco-manipulation循环,没有任何真实世界微调,仅使用RGB纯视觉输入。

另外,DoorMan是英伟达首个仅用RGB视觉、完全在仿真中训练、可零样本迁移到真实世界的人形机器人「开门」策略。
它在复杂的行走+操作+物体交互任务上,性能甚至超越人类遥操员。
「开门」是人形机器人最难的任务之一,因为它同时包含行走、精细操作等任务的重叠。
以往的方法,要么依赖特权状态(即力、位姿),要么真实数据昂贵、不可规模化。
而DoorMan诞生后,仅用了RGB,相同控制线,就让仿真直出真实世界。

此外,还有FLARE全新算法,是一种隐式世界模型的策略,核心思想是预测「未来对动作有用的表示」。

它不会去预测未来的像素,而是预测对动作有用的未来潜变量,让机器人在不断增加推理开销的情况下,学会提前想一想。
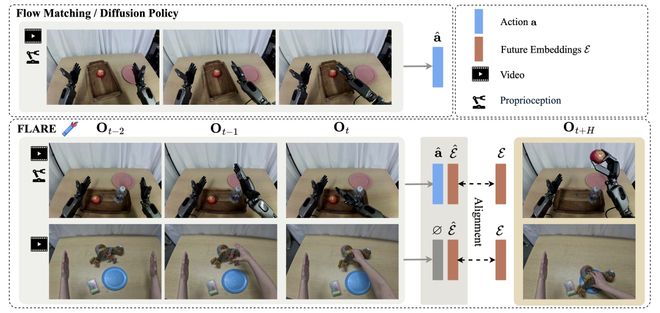
在训练中,FLARE在一个标准VLA策略模型中,引入了未来token——在Transformer中额外加入少量学习token。
实验结果显示,在4个真实操作任务,每个任务100条轨迹,GR-1平均成功率在95.1%。




左右滑动查看
三个教训,重注「视频世界模型」
这一年,所有人几乎都在为「氛围编程」(vibecoding)感到震惊。
休假这几天,JimFan还分享了对机器人这个蛮荒又混乱的西部世界的焦虑——
我在2025年学到的三个教训
1.硬件跑在软件前面,但硬件的可靠性,严重卡住了软件的迭代速度
我们已经看到了,许多堪称艺术品的工程成果,比如Optimus、e-Atlas、Figure、Neo、G1等等。
最强的AI还远远没有把这些前沿硬件的潜力榨干。
机器人的「身体」能做到的事情,明显多于它的「大脑」目前能指挥的范围。
但问题在于,照看这些机器人往往需要一整支团队全天候盯着。
和人类不一样,机器人不会自己从磕碰中恢复。过热、马达损坏、各种诡异的固件问题,几乎每天都在折磨工程师。犯错是不可逆的,而且一点都不留情。
到头来,唯一真正能规模化的,只有我的耐心。
2.机器人领域的基准测试,依然是一场史诗级灾难
在大语言模型圈子里,很多人已经把MMLU和SWE-Bench当成常识了。
机器人这边?先把手里的啤酒端稳。几乎没有任何共识:用什么硬件平台、怎么定义任务、评分标准是什么、用哪种仿真器,或者真实世界要怎么搭。
结果就是——每个人在自己临时为每次新闻发布现编的基准上,按定义都是SOTA。
每个人都会从100次重试里,挑一个最好看的demo拿出来秀。
2026年,我们这个领域必须做得更好,别再把可复现性和科学严谨性当成「二等公民」。
3.基于VLM的VLA,总感觉哪里不对
VLA指的是「视觉-语言-动作」(vision-language-action)模型,这是当前机器人「大脑」的主流路线。
套路也很简单:拿一个预训练好的VLMcheckpoint(模型权重),在上面嫁接一个动作模块。
但仔细想想就会发现,VLM本身是被高度优化来刷诸如视觉问答这类基准的。
这直接带来了两个问题:
(1)VLM里的大多数参数,其实都服务于语言和知识,而不是物理世界;
(2)视觉编码器被刻意训练去丢弃底层细节,因为问答任务只需要高层语义理解。但在机器人灵巧操作中,恰恰是这些细微细节最要命。
VLA的性能并没有任何必然理由会随着VLM参数规模一起提升。
问题在于,预训练目标本身就是错位的。相比之下,以视频世界模型作为预训练目标,看起来要合理得多。我已经在这条路线上下了重注。

有网友反问道,如果说世界模型是更优的预训练目标,但当前主流模型仍基于VLM构建并产出实际成果,而世界模型却主要用于策略评估和合成数据,而非直接控制?
JimFan称,它们都是2025年的模型,期待2026年下一个重大突破。
物理图灵测试,还有多远?
今年,在红杉资本一场闭门演讲中,JimFan首次引入了「物理图灵测试」概念。
短短20分钟视频,他生动有趣地介绍了当下具身智能的困局,大规模仿真如何挽救机器人未来,以及英伟达具身智能的路线图。

那究竟什么是「物理图灵测试」?
一场周末party让家里乱的一团糟(左),有人替你收拾了一切,还为你和伴侣准备了烛光晚餐(右)。
当你回家后看到一切,根本无法辨别这是人类的作品,还是机器的作品——这便是物理图灵测试核心想法。


那么,人类现在走到哪一步了?离这个目标还有多远?
三个生动的例子,让人爆笑全场。不得不承认,这就是当前具身智能的现实。



左右滑动查看
JimFan表示,Ilya曾说过预训练终结了,同时AI「石油」互联网数据几乎枯竭。
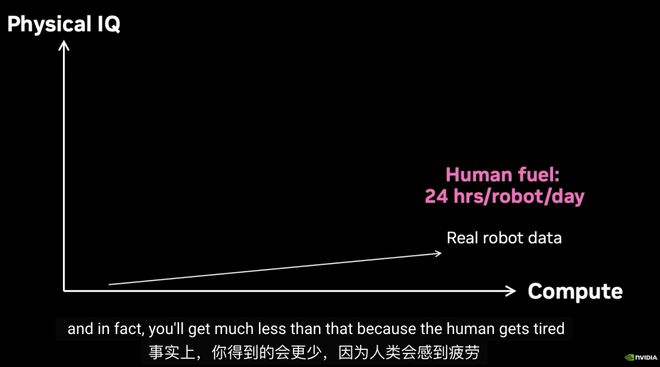
但若要和机器人领域数据相比,搞LLM的研究者就会明白有多么得天独厚了。

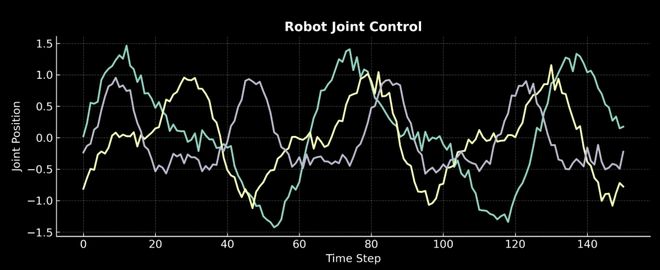
在英伟达,团队让机器人实操去收集数据,机器人关节控制信号,且数值随时间持续变化。
任何人无法从互联网上获取,必须通过自己收集才能完成。
他们具体是如何操作的?
其中,离不开一个重要的方式——遥操。它能够识别人手姿态并流式传输给机器人系统。

通过这种方式,可以教机器人从面包机中拿起面包,然后在上面淋上蜂蜜。
可以想象的到,这是一个非常缓慢极其痛苦的过程。
在JimFan看来,如果将真实数据收集放在坐标轴中展示,它根本无法实现ScalingLaw。
如何去打破这一困境,为机器人创造「无限能源」?
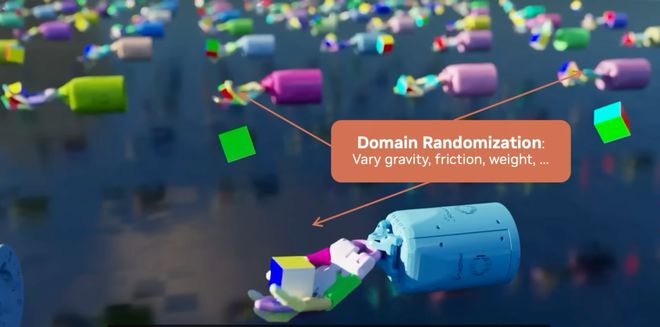
英伟达给出了一个更直接的解决方案——虚拟世界。
在仿真世界中,可以以1万倍于现实的速度训练,并通过「域随机化」(DomainRandomization)增强泛化能力。
也就意味着,系统在仿真中学会的任务,最终零样本迁移到真实世界。

接下来,JimFan提出了仿真世界模拟的三个阶段——
它需要精确建模机器人与物理环境,优点在于快、可控、可迁移,而缺点是构建成本高,强依赖人工建模。
大量3D资产、场景、纹理由模型自动生成,仍结合传统物理引擎,在真实与仿真之间取得工程上「足够接近」。
可利用视频扩散模型,直接生成「可交互的未来」,不再显示建模物理规则。
它的优势在于,能处理软体、液体等复杂物理,通过语言生成「反事实世界」。
JimFan还将其称之为「数字游牧者」(DigitalNomad)。
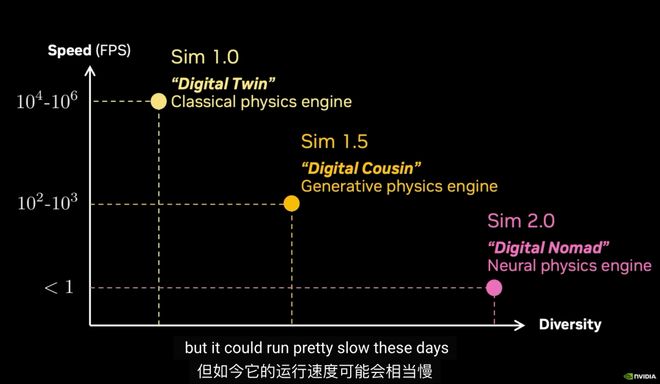
再回到当初这张坐标图,机器人数据ScalingLaw很好地呈现了出来。
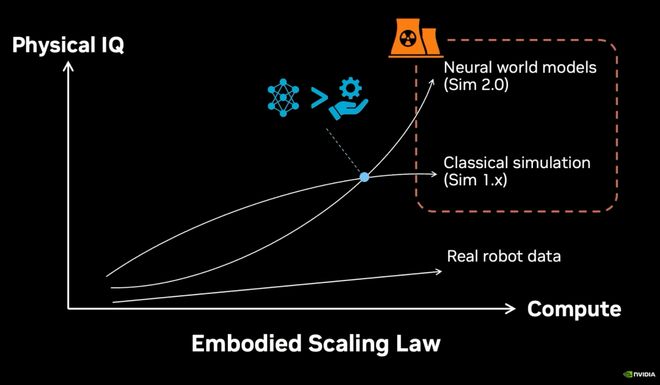
最终,所有这些数据流入了一个统一的模型,即VLA——输入:语言+视觉,输出:动作控制。
也就是如上提到了GR00T系VLA基础模型,从N1,到N1.5,再到N1.6三个版本不断升级迭代。
最后,JimFan指出物理AI的未来,不只是更聪明的机器人,而是一种新基础设施。
比如PhysicalAPI、物理APPStore,让技能可以像软件一样被分发到机器人系统中。
几天前,谷歌大佬LoganKilpatrick预测,2026年将成为具身AI的重要一年。
用不了不久,我们将在现实世界中看到更多的机器人。
参考资料:
https://x.com/DrJimFan/status/2003879965369290797?s=20
https://www.youtube.com/watch?v=_2NijXqBESI
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!