qwen3.6 确实强,已经达到上一代claude 4.5的水平,我又使用了一个ops的蒸馏版。现在用Q8量化本地生产级开完全代替了付费大模型。以我的使用量,全年节省2000美元的token成本,且不需要看anthropic的脸色还得特么科学上网。这就是我为什么可以决策买rtxpro6000的一个基本ROI核算。这张卡8000多美元,仅靠编程的token消耗,固定资产折旧就拉平成本了。且不说有了这个免费的神器以后我的本地token使用量将远远超过定额,以及各种其他模型本地AI的能力就白送了。
以往的经验看,我个人的节奏比行业快一年左右,也就是说明年中期,大部分在线烧token的中小公司都会转向本地部署AI服务器,将OPEX 费用支出转化成CAPEX 资本支出。在显卡这一块,保值率和耐用度远超一般服务器。比如rtxpro6000这张卡的折旧摊销可以拉到八年。虽然单价高,但是赚钱的。
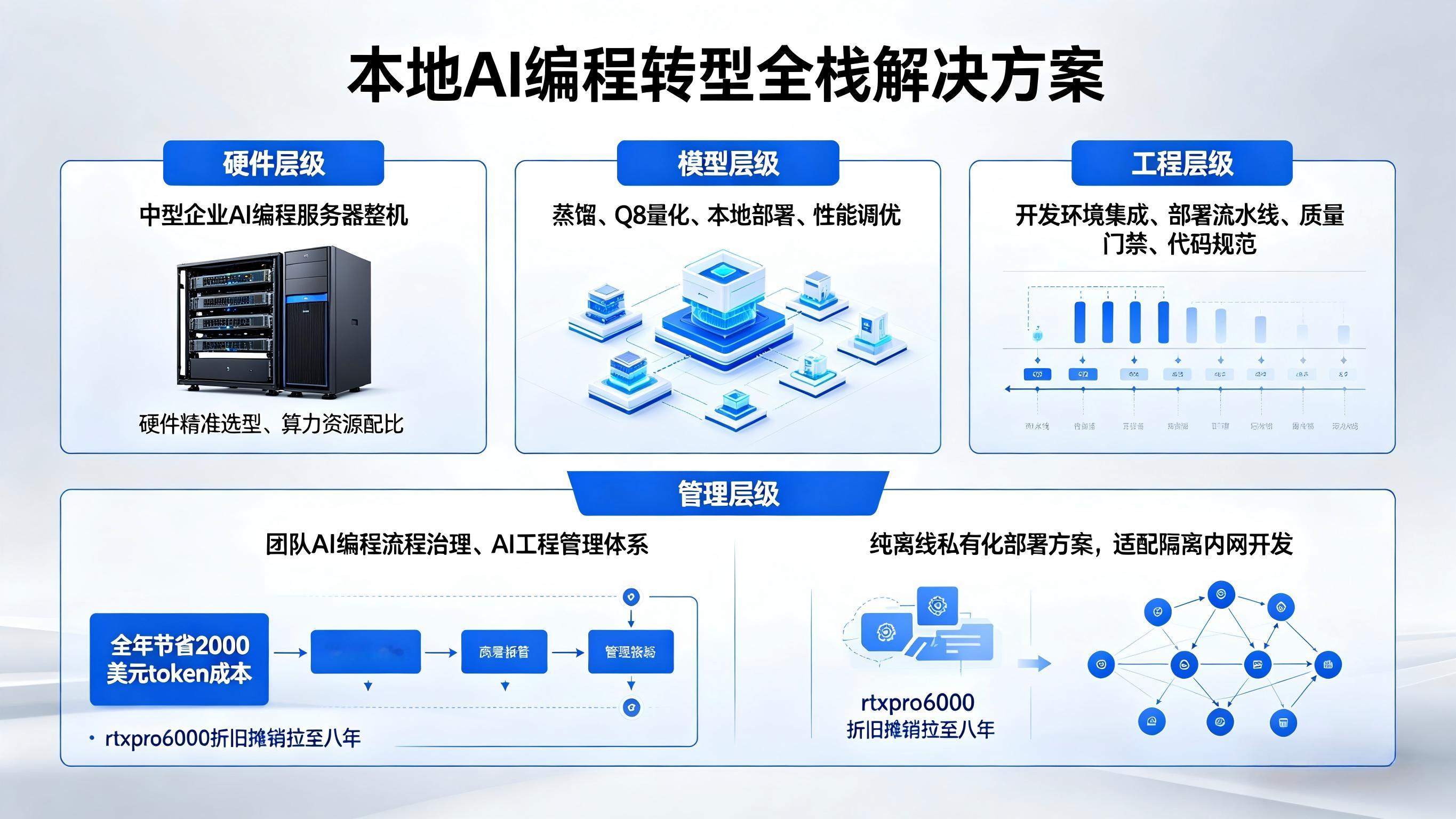
面向中型以下企业的全套本地AI coding硬件选型规划,模型部署调优,软件开发环境配置集成,部署流水线,质量门禁控制,团队编程AI化治理,AI工程管理经验,完全可以指导企业全面向低成本可持续AI编程转型。重要的是可以实现完全离线,使大量隔离开发环境具备接近在线编程的应用能力,安全合规,成本可控。现在啥都敢往AI上甩真是无知者无畏。
硬件层级:中型企业 AI 编程服务器整机 / 硬件精准选型、算力资源配比模型层级:蒸馏、Q8 量化、本地部署、性能调优工程层级:开发环境集成、部署流水线、质量门禁、代码规范管理层级:团队 AI 编程流程治理、AI 工程管理体系合规层级:纯离线私有化部署方案,适配隔离内网开发
有人可能会问,你这套体系比原生的大型来强嘛。我可以肯定地告诉你,绝对比原生大模型强,因为两者根本不是一个维度的东西。我这是整体解决方案,原生大模型在我这里只是一个infra的能力底座,有什么资格与我相提并论?发动机再牛逼也不能自己跑。
有咨询需求的老板,可以联系。