【国产大模型编程实测:差距早已不是能不能写,而是怎么写】
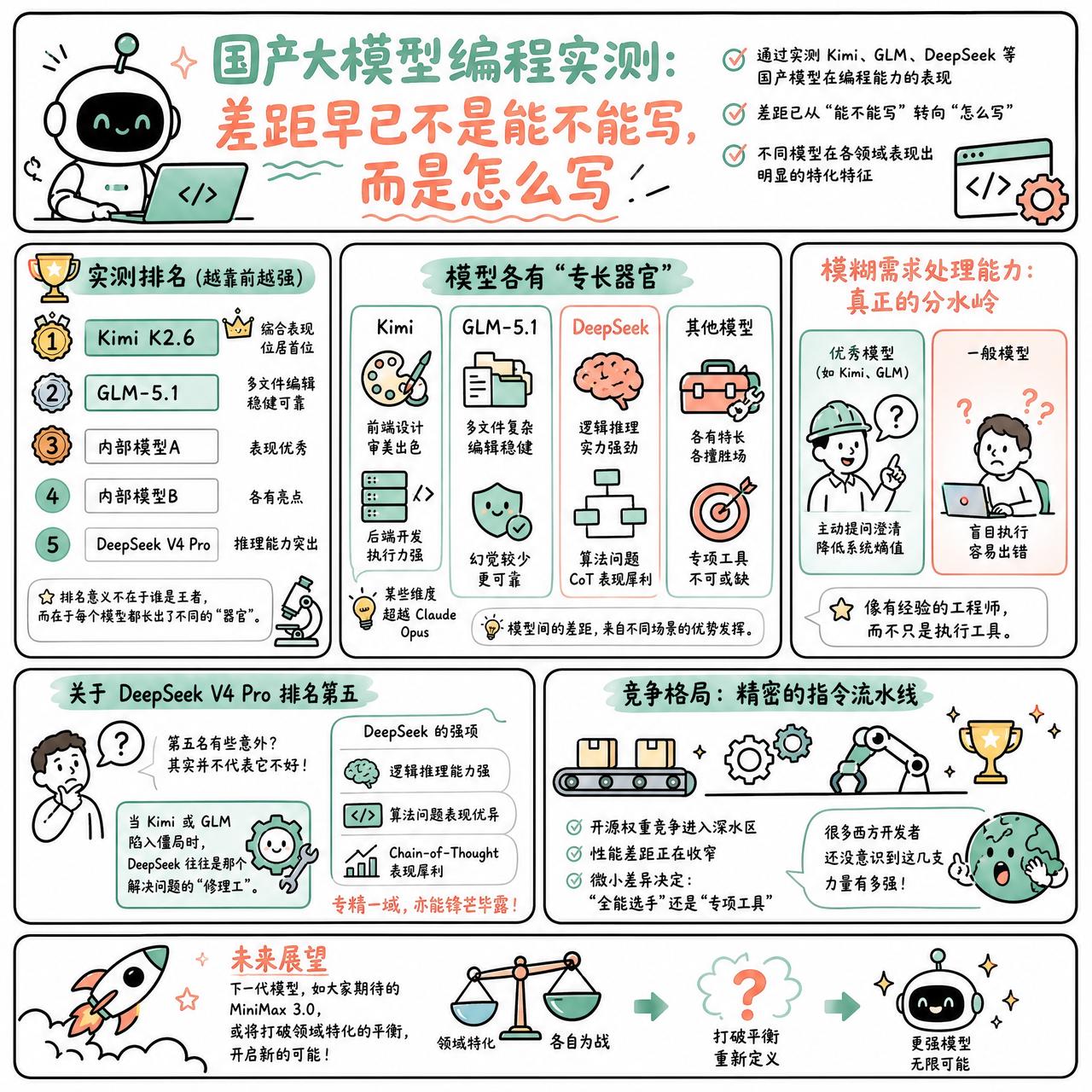
快速阅读:通过对 Kimi、GLM、DeepSeek 等国产模型在编程能力的实测,发现模型间的差距已从“能不能写”转向“怎么写”。不同模型在前端设计、后端逻辑、代码审查及复杂推理上表现出明显的领域特化特征。
国产编程模型现在的竞争,有点像是在极其精密的指令流水线上比拼调度效率。
最近的一份实测排名把 Kimi K2.6 放在了首位,紧随其后的是 GLM-5.1。这种排名的意义不在于谁是绝对的王者,而在于每个模型都长出了不同的“器官”。Kimi 在前端设计和后端开发上表现出很强的审美与执行力,甚至有人认为它在某些维度超过了 Claude Opus。GLM-5.1 则在处理多文件复杂编辑时表现稳健,幻觉较少。
有网友提到 DeepSeek V4 Pro 被排在第五位有些令人意外。其实第五名并不代表它不好,DeepSeek 的强项在于逻辑推理,尤其是在算法问题上的 Chain-of-Thought 表现非常犀利。甚至有人发现,当 Kimi 或 GLM 陷入僵局时,DeepSeek 反而能成为那个解决问题的“修理工”。
更有意思的观察点在于模型处理模糊需求的能力。有观点认为,真正的分水岭在于面对不明确的规格说明时,模型是选择盲目执行导致错误,还是会主动停下来提问。Kimi 和 GLM 在这一点上做得更好,它们更像是有经验的工程师,会通过澄清问题来降低系统熵值。
现在的局面是,开源权重的竞争已经进入了深水区,很多西方开发者甚至还没意识到这几支力量有多强。模型之间的性能差距正在收窄,这种微小的差异决定了它们是在不同场景下作为“全能选手”还是“专项工具”存在。
或许下一代模型,比如大家期待的 MiniMax 3.0,会彻底打破这种领域特化的平衡。
x.com/llmdevguy/status/2052449602910015962