一图总结中美大模型竞争要点
最近美国开发者的“痛点”是,用Anthropic的Claude Opus 4.7跑编程、Agent,十来分钟,20美元的套餐就token额度耗光了,任务跑得断断续续的。有的转向OpenAI的Codex,说虽然性能稍差一点点,但同样的钱可以跑多几倍的任务,还不卡。Anthropic说是算力不足,要加紧上算力,刚租了马斯克xAI解散让出的算力中心。
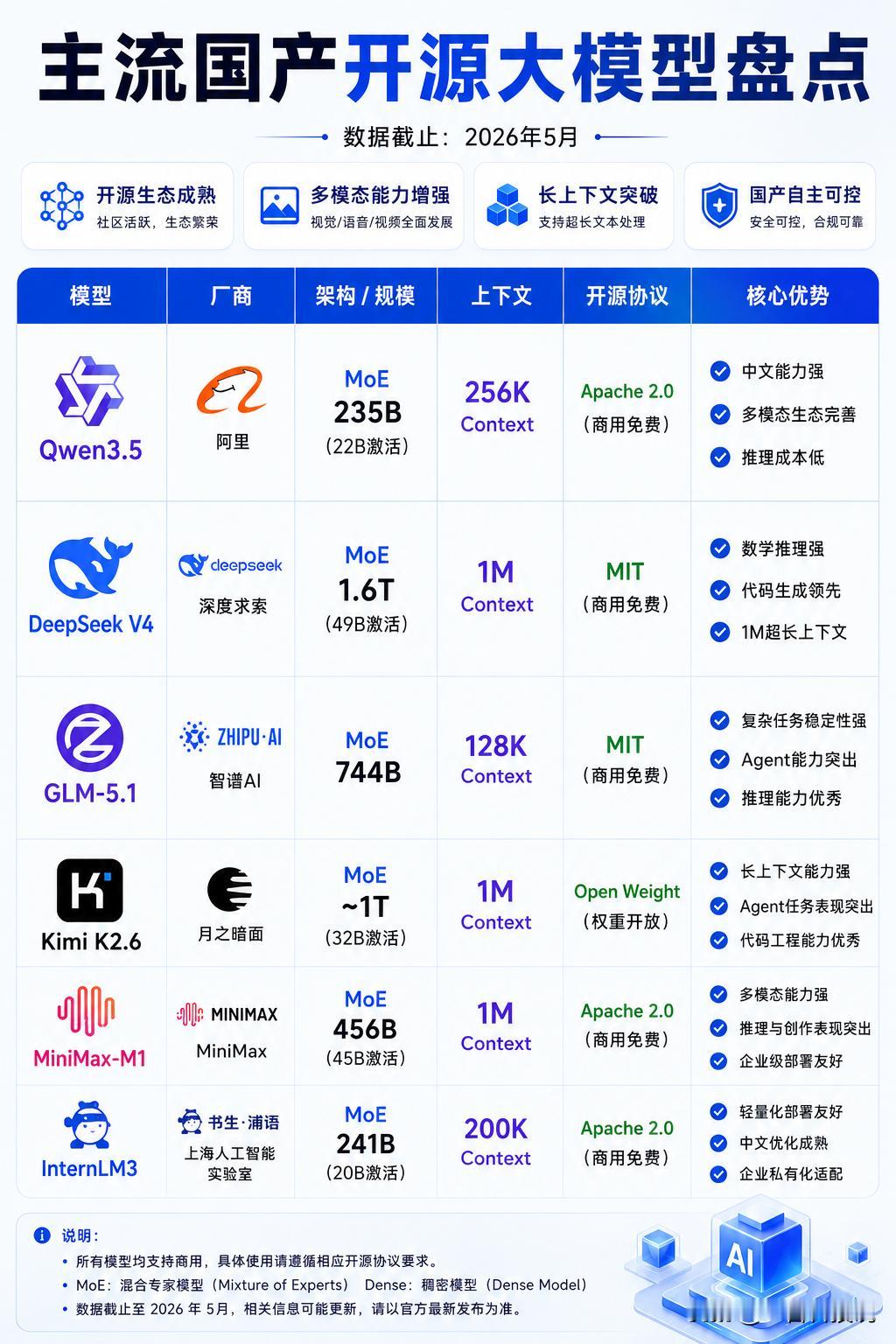
另一方面,中国用户和部分美国用户在用中国低价开源大模型。最近DeepSeek V4的口碑是,用起来真好便宜,几块钱就能用巨量token,完全没有“花钱”的心理负担。但中国开源大模型顶尖性能不足,是最大的问题。
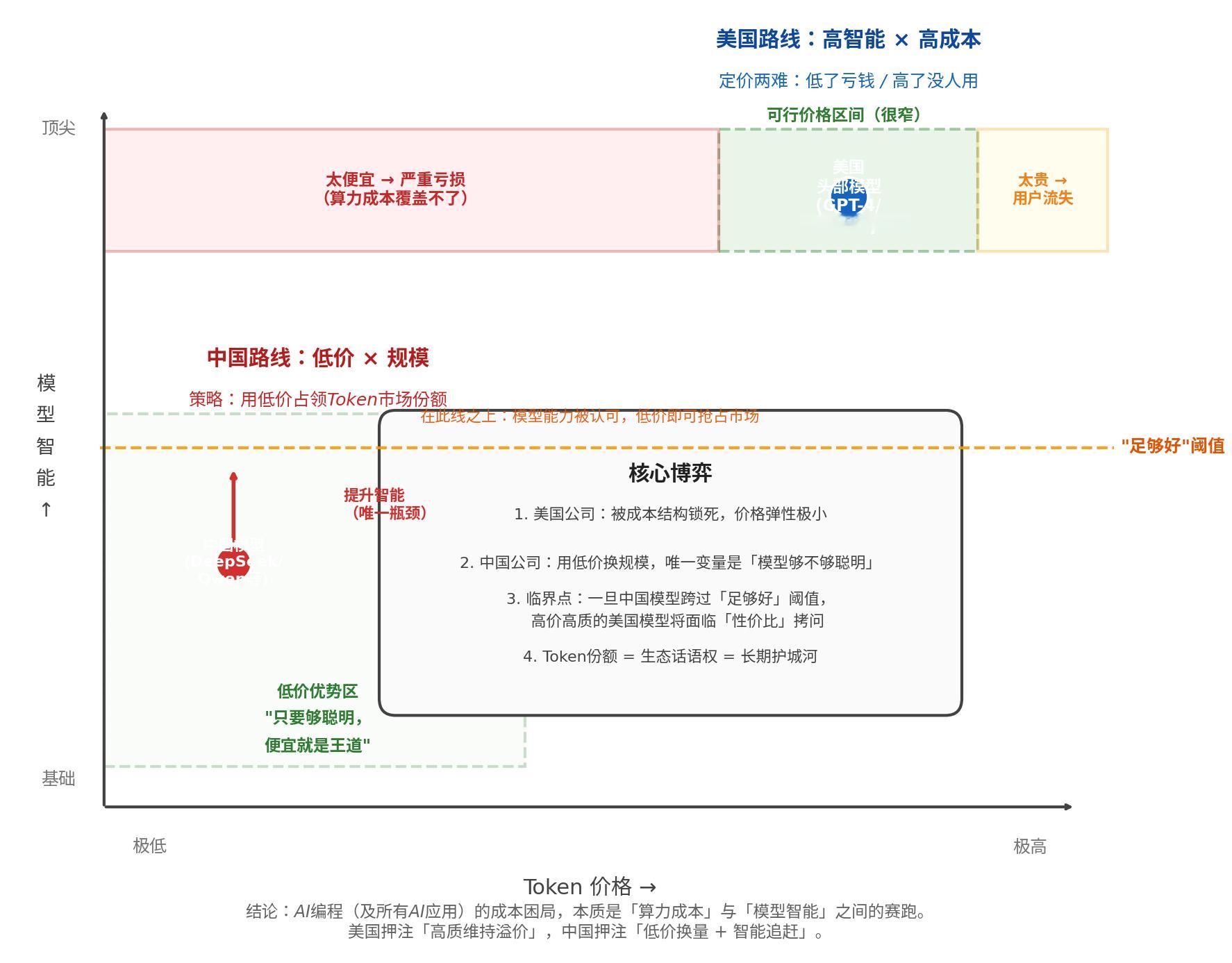
图中总结了中美大模型竞争发展的要点。美国头部大模型处于智能高位区间,但麻烦是,token价格定高了不行、定低了也不行。红色是定价低的区间,美国算力中心和大模型研发成本极高,低了无法覆盖研发和推理成本,模式不通。如果定价过高,用户流失,实在受不了充钱时的心痛。token用量大的时候,就等于以前中国倒霉用户用昂贵的国外上网费用下载电影,一夜之间发现面对上万的费用。只用定价不高不低,既能覆盖运营成本,又能有足够需求,但这个价格区间很窄,如每百万token要0.5美元。
而中国大模型处于智能低位区间,已经有了一个“低价优势区间”。由于十分之一至百分之一以下的价格优势,一般性的智能任务,中国大模型抢占用户有优势。典型就OpenRouter平台上的开发者,积极使用中国大模型降低开发成本,应用在一般性任务上。
但中国大模型的性能在业界还面临“好用”的门槛,就是图中的黄线,性能要“足够好”。如果模型性能不够好,就没有办法在黄线以上来抢美国公司的token份额。目前美国头部大模型还没有感觉到本质的威胁,强调“好用”就可抵挡攻势。
目前中国大模型研发的任务是,不断扩大“低价优势区间”,在越来越多领域取得“低价又好用”的口碑。不需要完全追上美国大模型绝对性能,相比自己不断提升都很有意义。
等中国大模型性能到了一定程度,美国大模型就真正面对竞争了。那时不仅因为成本问题,定价区间有困难。如果客户被中国大模型抢跑一大片,如何定价就更困难了。甚至根本定不出来,怎么都会亏钱。