最近看到百度文心 5.0 的一个技术细节,觉得挺有意思的,叫做弹性训练范式。
听起来很学术,但解决的是个很实际的问题。
简单说就是,以前训练 AI 模型就像定制西装,想要什么尺码就得单独做一套。
但文心 5.0 搞了个新玩法,一次训练就能得到好几个不同规格的模型。有点像买了一件可以调节大小的衣服,需要的时候拉一拉、缩一缩就行。
在我的印象里,AI 模型训练一直都是个烧钱又费时的活儿,每次调整参数都得重新来过。现在居然能做到这么灵活,确实让人眼前一亮。
那这个弹性训练到底是怎么回事呢?
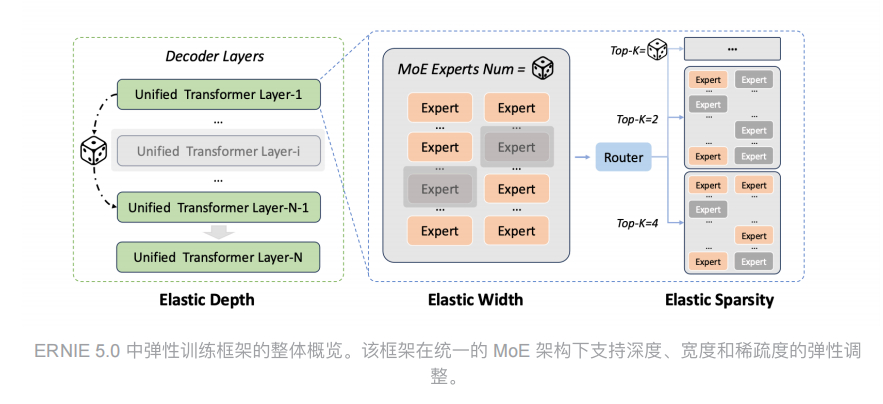
1️⃣ 一次训练,多种规格
这是文心 5.0 弹性训练最核心的特点。
传统的模型训练就像是流水线生产,你想要一个 100 亿参数的模型,就得专门训练一次;想要 50 亿参数的,又得重新来。但弹性训练不一样,它在训练过程中就考虑到了不同规模的需求。
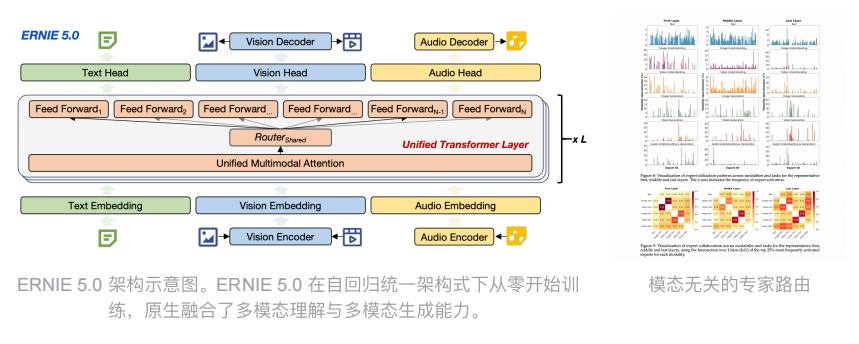
技术上来说,它是通过动态调整模型的深度、宽度和稀疏度来实现的。深度就是模型有多少层,宽度是每层有多少神经元,稀疏度则是激活多少参数。
训练的时候,这三个维度都可以灵活变化,最后你就能从同一个训练过程中提取出不同规格的模型。
这样做的好处显而易见。
首先是省钱,不用为每个规格都跑一遍完整的训练流程。
其次是省时间,整个开发周期能缩短不少。
更重要的是,这些不同规格的模型都来自同一个训练基础,质量相对有保障。
2️⃣ 适配不同硬件场景
你可能会问,为什么需要这么多不同规格的模型呢?答案很简单,因为应用场景差异太大了。
比如说,你在云端服务器上跑模型,那硬件资源充足,用个大模型完全没问题。
但如果要把模型部署到手机上,或者一些边缘设备上,那就得考虑算力和内存限制了。
以前的做法是专门为移动端训练一个小模型,但现在有了弹性训练,直接从同一个训练过程中拿一个小规格的版本就行。
这种灵活性在实际应用中特别有用,比如我看到有些场景是这样的,用户在手机上发起请求,先用本地的小模型做初步处理,如果遇到复杂问题再调用云端的大模型。
这种大小模型协同工作的方式,既保证了响应速度,又兼顾了处理能力。
而且随着端侧 AI 越来越火,这种能够灵活适配不同硬件的训练方式,可能会成为标配,毕竟不是每个场景都需要动用最强算力,有时候够用就好。
3️⃣ 技术实现的巧妙之处
从技术角度看,弹性训练其实挺考验功力的,因为你不能简单地把一个大模型砍掉一半就当小模型用,那样效果会很差。
文心 5.0 的做法是在训练过程中就让模型学会适应不同的规模。
具体来说,它会在训练时随机采样不同的深度、宽度和稀疏度配置,让模型在各种规格下都能保持良好的性能。
这就像是让运动员在不同强度下都能保持状态,而不是只擅长某一种训练强度。
这种训练方式的难点在于平衡。你既要保证大模型的性能不受影响,又要让小模型也能用得起来。这中间需要大量的调优工作,包括损失函数的设计、训练策略的调整等等。
不过从结果来看,这个技术路线是走通了的。文心 5.0 能够在不同规模下都保持不错的效果,说明这套方法论是有效的。
不过说实话,我最大的感受是 AI 训练正在变得越来越工程化。以前大家更多关注的是怎么把模型做大、做强,但现在开始考虑怎么让训练过程更高效、更灵活了。
这其实反映了整个行业的成熟。
当技术发展到一定阶段,单纯追求性能指标的意义就没那么大了,怎么降低成本、提高效率反而成了关键。弹性训练就是这个思路下的产物,它不是为了刷榜单,而是为了解决实际问题。
从趋势来看,我觉得未来会有更多类似的技术出现。比如怎么让模型训练更节能,怎么在训练过程中就考虑到部署需求,怎么让模型更新变得更轻量等等。
而这,可能才是推动 AI 真正落地的关键。