机器之心报道
编辑:冷猫、Panda
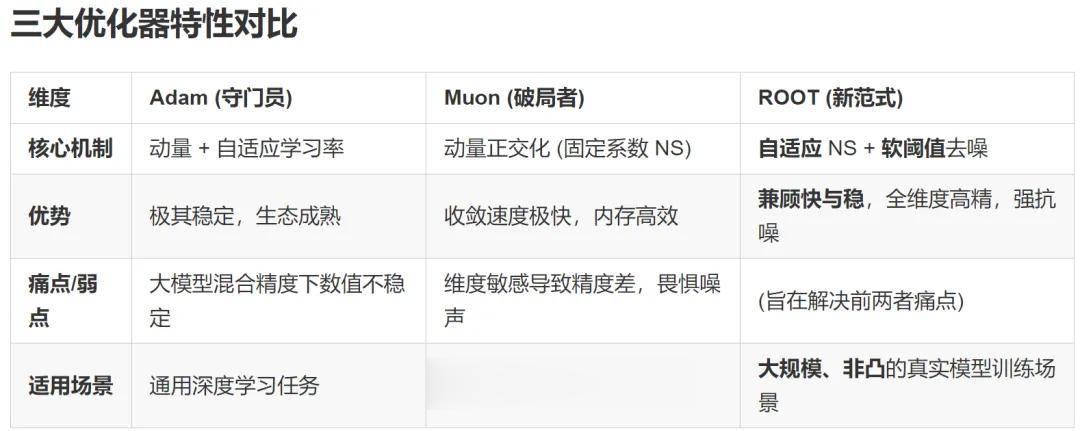
在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
它们一个是久经沙场的「守门员」,凭借动量和自适应学习率统治了深度学习的半壁江山,却在面对十亿级参数的混合精度训练时,常常因数值不稳定性而显得力不从心;一个是横空出世的「破局者」,试图通过将权重矩阵视为整体来重塑训练几何,却因为一刀切(one-size-fits-all approach)的系数设计和对异常值噪声的极度敏感,在鲁棒性上留下了缺口。
当训练规模不断指数级膨胀,我们是否只能在 Adam 的「稳」与 Muon 的「快」之间做单选题?
华为诺亚方舟实验室的最新力作 ROOT (Robust Orthogonalized OpTimizer) 给出了否定的答案。
作为一款直击痛点的鲁棒正交化优化器,ROOT 不仅精准修复了 Muon 在不同矩阵维度上的「精度近视」,更通过巧妙的软阈值机制为梯度噪声装上了「减震器」。它正试图用更快的收敛速度和更强的稳定性,为大模型训练建立一套全新的、兼顾精确与稳健的优化范式。
 论文标题:ROOT: Robust Orthogonalized Optimizer for Neural Network Training
论文地址:https://arxiv.org/abs/2511.20626
开源地址:https://github.com/huawei-noah/noah-research/tree/master/ROOT
作者:Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, Yunhe Wang
机构:华为诺亚方舟实验室
论文标题:ROOT: Robust Orthogonalized Optimizer for Neural Network Training
论文地址:https://arxiv.org/abs/2511.20626
开源地址:https://github.com/huawei-noah/noah-research/tree/master/ROOT
作者:Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, Yunhe Wang
机构:华为诺亚方舟实验室 LLM 优化史:从 SGD 到 ROOT
要理解这项工作的重要性,我们需要先了解优化器(Optimizer)在 LLM 训练过程中至关重要的地位。
简单打个比方:在深度学习的浩瀚宇宙中,优化器扮演着飞船「引擎」的角色。
其中,最早的优化器是 SGD(Stochastic Gradient Descent),即随机梯度下降。作为深度学习的基石,它确立了神经网络训练的基本范式:通过计算小批量数据的梯度来迭代更新参数。
SGD 是最经典的一阶优化方法。然而,在面对高维且复杂的损失函数曲面(Loss Landscapes)时,原始的 SGD 往往难以兼顾收敛速度与稳定性。为了帮助模型更高效地穿越复杂的「山谷」找到极小值,研究者们在 SGD 的基础上引入了动量机制,这不仅成为了 SGD 的标准配置,也为后来更复杂的自适应方法奠定了基础。
后来,以 Adam 和 AdamW 为代表的自适应方法崛起,成为训练深度学习模型的「事实标准」。
它们通过引入动量和逐参数(Per-parameter)的自适应学习率,让收敛效率大幅超越 SGD。然而,这类方法的底层逻辑是将模型参数视为独立的「标量」或向量进行更新。当模型参数量突破十亿大关,这种忽略参数矩阵内部结构相关性的处理方式,在混合精度训练中逐渐暴露出了数值不稳定的缺点。
为了突破这一瓶颈,以 Muon 为代表的矩阵感知型优化器应运而生。

Muon 不再仅仅盯着单个参数,而是将权重矩阵视为一个整体。它利用 Newton-Schulz 迭代对动量矩阵进行正交化处理,从而在不增加额外计算复杂度(保持 O (N))的前提下,规范了更新的几何结构。
这种方法在理论上等同于在谱范数下进行最速下降,显著提升了训练效率和显存利用率。
尽管 Muon 开启了新的一页,但研究人员发现它并非完美无缺。
华为诺亚方舟实验室的分析指出,现有的正交化优化器存在两个核心局限:
算法鲁棒性的缺失: 现有的 Newton-Schulz 迭代通常使用一组固定的系数。然而,神经网络不同层的权重矩阵形状各异(从正方形到极度扁平的矩形),固定系数在某些维度下会导致近似误差激增,产生「维度脆弱性」。 对梯度噪声的缺乏防御:在大规模训练中,异常数据往往会产生极大幅度的梯度噪声。现有的自适应优化器对这些噪声异常敏感,不仅会破坏更新方向,还可能导致训练彻底失稳。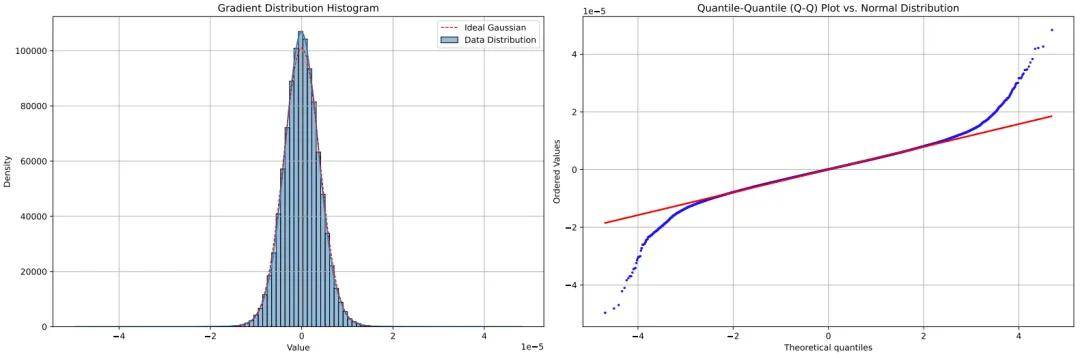
随机梯度中异常值噪声的概念可视化。大多数梯度值集中在中心附近,存在一个高幅度异常值的尾部。这些异常值会不成比例地影响优化过程。
正是在这种既要「矩阵感知的快」又要「传统方法的稳」的博弈中,ROOT 应运而生,试图填补这一关键的拼图空缺。
ROOT 优化器:双管齐下
前文我们已经介绍过,现有的正交化优化器(尤其是 Muon)存在的核心缺陷。
ROOT(Robust Orthogonalized OpTimizer)的核心方法,是为正交化优化器做出了针对性的鲁棒性增强,让优化器在快速和稳定「两手抓」。
拒绝「一刀切」
正交化优化器的算法不稳定,核心问题源于正交化系数的「一刀切」。
具体来说,Muon 里 Newton-Schulz 迭代的系数 a、b、c 是固定常数。华为诺亚方舟的研究者们发现,这会引发不同维度矩阵的脆弱性。
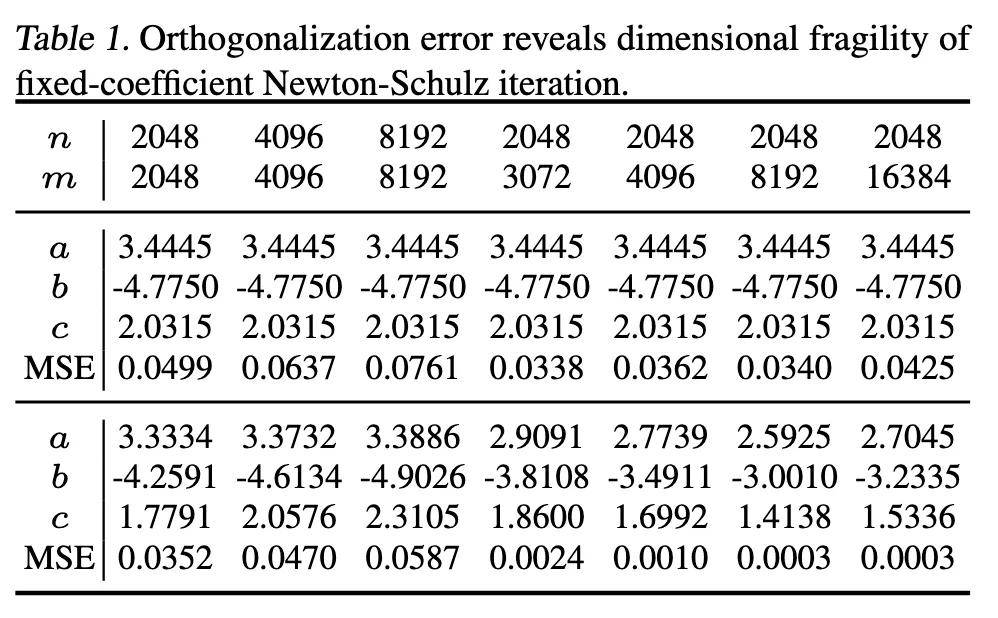
正交化误差揭示了固定系数 Newton-Schulz 迭代在维度上的脆弱性。
从上表中的数据能看出,矩阵形状(维度或长宽比)一变,正交化误差会大幅波动。尤其是方阵更吃亏,方阵始终产生最高的 MSE 值,比非方阵配置有显著的差距。
这种维度敏感性在优化过程中造成了固有的脆弱性,因为不同维度的层获得的正交化质量完全不同,损害了梯度更新的一致性和可靠性。
为了解决这种维度脆弱性并构建维度鲁棒的正交化过程,研究者们提出了具有细粒度、特定维度系数的自适应 Newton-Schulz 迭代(AdaNewton)。

然而,系数针对每个矩阵维度的特定奇异值分布进行了优化。这种方法为提高正交化精度提供了理论保证。
这些系数可以在训练期间与模型参数联合优化,允许正交化过程自动适应每种层类型的属性。这种细粒度的适应代表了一种范式转变:从脆弱的维度敏感正交化转向鲁棒的维度不变正交化,确保了整个网络的更新质量一致。
过滤「异常值」
大模型训练的梯度常出现「重尾现象」:小批量梯度经常被异常值噪声污染,这些噪声包含幅度异常大的梯度分量,这些异常值严重影响到了 Muon 中正交化过程的稳定性。
更糟的是,Newton-Schulz 迭代的多项式性质会放大离群噪声,造成不稳定,甚至可能引发 Transformer 的 attention logits 爆炸的严重问题。
为了解决这一问题,华为诺亚方舟的研究者们的做法很直接干脆:把梯度 Mₜ 分解为「正常部分」和「异常部分」两个分量:
基础分量 Bₜ:包含表现良好的梯度信息。 异常分量 Oₜ:代表异常的大幅度元素。正交化仅应用于鲁棒分量 Bₜ,而丢弃异常值分量 Oₜ。

这个函数如果值的幅度高于阈值 ε,则提取超出范围的异常值。
在数学上,软阈值可以被解释为硬裁剪(hard clipping)的一种连续、可微的替代方案。软阈值应用了一种平滑的收缩操作,在抑制极端值的同时保留了梯度幅度的相对排序。

完整的 ROOT 优化器算法
ROOT 的实验表现:真的又稳又快
为了验证 ROOT 是不是真的快速又稳定,华为诺亚方舟实验室训练了一个 1B Transformer 模型。他们的测试非常严苛,涵盖了从预训练 Loss 到下游任务的多项基准,甚至跨越到了视觉任务领域。值得注意的是:「所有模型都是在昇腾 NPU 分布式集群上训练的。」
而最终得到的结果也非常亮眼,证明了 ROOT 优化过程的表现极具竞争力。
首先,在预训练效率上,ROOT 展现了卓越的收敛能力。
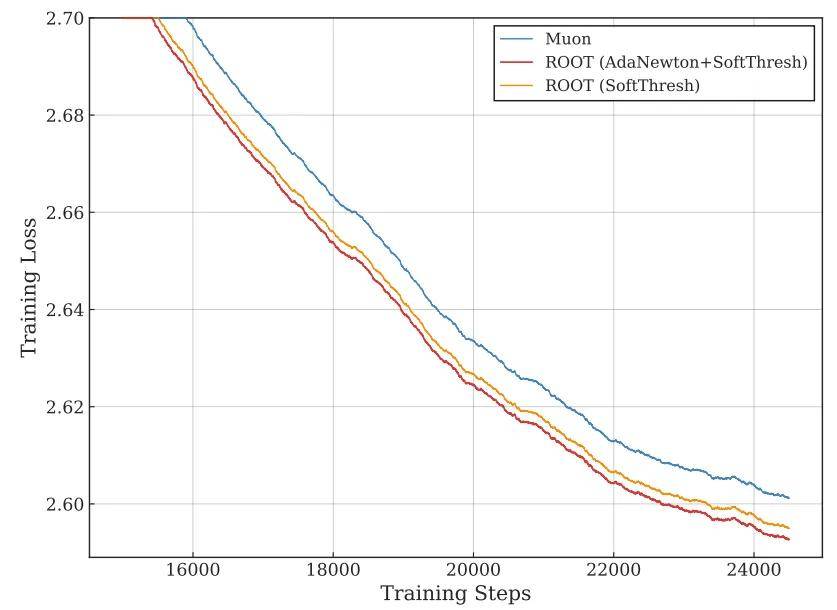
使用 10B Token 的训练损失对比
如上图所示,在 10B token 的大规模预训练实验中,两个 ROOT 变体(仅软阈值版与完整版)的训练损失均始终保持在 Muon 的 Loss 曲线下方。最终,ROOT 的训练损失达到 2.5407,比 Muon 基线低 0.01。
而更深入分析显示,Muon 由于采用固定系数,在训练过程中存在较大的近似误差;而 ROOT 凭借自适应系数,始终保持着更接近真实 SVD 的正交化精度 。
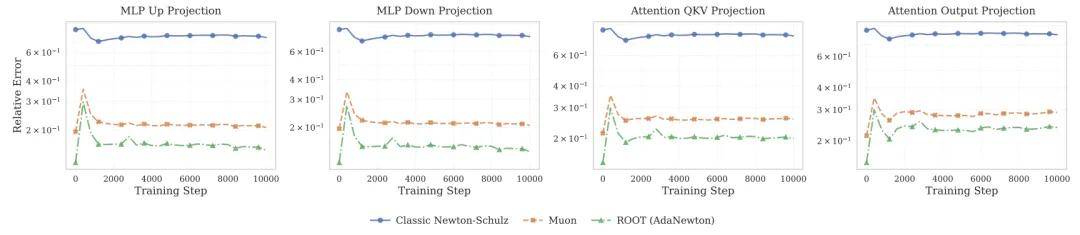
相对于真实 SVD 的正交化精度
在多项下游任务基准上,ROOT 也带来了全面的提升:ROOT 取得了 60.12 的平均分,不仅击败了传统霸主 AdamW(59.05),也超越了其直接竞争对手 Muon(59.59)。

在 9 个标准 LLM 基准上的零样本性能,其中 ROOT 在 6 个基准上领先
同时也能看出 ROOT 具有广泛适用性:无论是在考察常识推理的 PIQA,还是考察科学知识的 SciQ,ROOT 都展现出了极具竞争力的性能。
不仅如此,ROOT 还表现出了非常出色的跨模态泛化能力:在计算机视觉领域(训练 ViT 模型识别 CIFAR-10 数据集)的测试中,ROOT 同样证明了其强大的泛化能力。
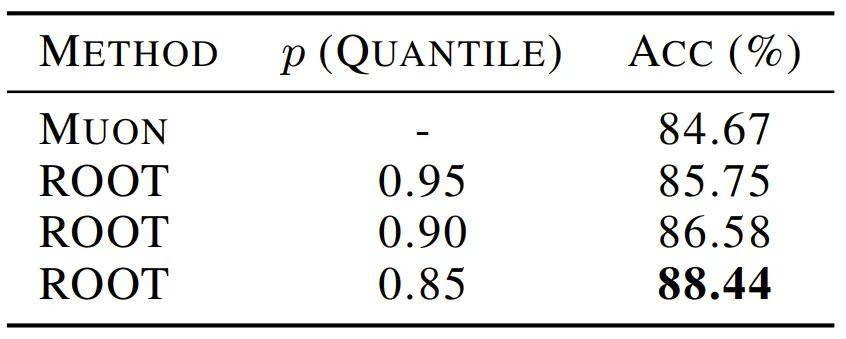
在 CIFAR-10 上的 Top-1 测试准确度
特别是在引入软阈值机制后,ROOT 能够有效抑制视觉数据中的梯度噪声,取得了 88.44% 的 Top-1 准确率,显著优于 Muon 的 84.67% 。这表明 ROOT 的「去噪+正交化」范式具有极强的跨领域普适性。
该团队也进行了消融实验,证明了 ROOT 各组件的有效性。
ROOT 或将开启新的优化器时代
在 LLM 训练日益昂贵且复杂的今天,华为诺亚方舟实验室提出的 ROOT 优化器,通过 AdaNewton 和软阈值去噪两大创新,成功在 Muon 的高效基础上补齐了鲁棒性这块短板 。
ROOT 不仅在理论上保证了不同维度矩阵更新的一致性,更在实战中证明了其在抗噪、收敛速度和最终性能上的全面优越性。
ROOT 的代码将会开源,随着更多研究者将其投入到更大规模的万亿级模型训练中,我们有理由相信,它很有可能会开启一个新的优化器时代。
正如这篇论文的结语所言:「这项工作为开发鲁棒的优化框架开辟了有前景的方向,这些框架能够处理未来语言模型日益增加的复杂性和规模,从而可能实现下一代 AI 系统更可靠、更高效的训练。」
凭借此一贡献,华为诺亚方舟实验室展示了其「深潜」的创新特质,秉持理论研究与应用创新并重的理念,致力于推动人工智能领域的技术创新和发展:不随波逐流于表层的应用创新,而是潜入深海,解决最基础、最困难、但影响最深远的优化理论问题。这不仅展示了其强大的科研硬实力,更体现了其作为行业领军者,致力于构建更高效、更鲁棒的下一代 AI 训练范式的战略远见。
团队简介
本文有两位共一作者,他们都是华为诺亚方舟实验室研究员。据公开资料显示,其中韩凯(Kai Han)现为华为诺亚方舟实验室专家研究员,博士毕业于中国科学院软件所,硕士和本科分别毕业于北京大学和浙江大学。其主要研究方向为高效深度学习和 AI 基础模型,已在 AI 领域顶会顶刊发表论文 50 余篇,谷歌学术累计被引 2.1 万余次,其中 GhostNet 和 TNT 入围 PaperDigest 年度最具影响力论文榜单。他还担任 NeurIPS、ICML、ICLR、CVPR、ICCV、AAAI 和 ACMMM 等顶会领域主席,入围斯坦福全球 Top 2% 科学家和爱思唯尔中国高被引学者榜单。
另外,今年 3 月接任华为诺亚方舟实验室主任的王云鹤也是本文的通讯作者。
关于该方法更多信息,请参阅原论文。