很多人不知道,现在AI获取知识的方式,正在分化成两条路线。
先聊一件我觉得很离谱的事情,就是Anthropic这家公司为了训练模型,甚至选择拆书......
他们发起了一个叫「巴拿马计划」的项目,从图书馆、二手书店、像斯特兰德这样的实体书店买书,然后用液压切割机把数百万册书整齐地切开,再用高速扫描仪扫描书页,最后找回收公司处理掉这些被拆解的书。
很多人第一反应是:这也太暴力了吧?
但我看到的问题是,为什么Anthropic要这么大费周章?
结合最近的行业动态,我意识到:大模型竞争已经从参数战,转向了数据战。而OCR,正在成为这场战争里各家必争的入口。
1
Anthropic拆书这件事,其实不是孤例。
在拆实体书之前,Anthropic就因为盗版电子书惹过争议。2021年,他们联合创始人本·曼恩从LibGen下载了数百万册书籍。
而且,Anthropic不是唯一这么干的。
Meta也被曝光从LibGen窃取了数百万册书,内部员工还在通讯里写:“如果媒体报道暗示我们使用盗版数据集,可能会削弱我们在监管机构那边的谈判地位。”
为什么各家都盯上了实体书?
答案很简单:互联网数据快被榨干了。
过去两年,大模型竞争主要集中在参数规模上。
但现在行业共识是,高质量的实体数据,正在成为下一代模型竞争的关键资源。书里的知识密度、结构化程度,远超互联网碎片化内容。
所以Anthropic才会不惜成本地去拆书、扫描、数字化,然后喂给模型。
2
如果说Anthropic拆书还只是个开始,那GPT之父的实验就更能说明问题了。
4月29日,Alec Radford发布了一个叫talkie的模型,总参数130亿,训练数据全部来自1931年之前的旧文献——书籍、报纸、期刊、科学论文、美国专利、判例法,这些数据全靠他手动OCR近百年前的文献。
结果这个只读过19世纪知识的模型,仅通过少样本学习,竟然能写出正确的Python程序。也就是说,模型可以用19世纪的知识做推理,而不只是检索。
这件事最值得注意的,是OCR在这里扮演的角色:它是AI获取知识的第一步。
OCR的价值已经变了,它不再只是一个"识别文字"的工具,而是连接现实世界知识与AI能力的基础设施。
3
现在行业里,AI获取知识的方式正在分化成两条路线。
第一种路线,以Anthropic为代表:买书 → 拆书 → 扫描 → 数字化 → 喂给模型。
本质上,是把现实世界标准化,让机器容易处理。
因为传统OCR对环境要求很高:书页最好是平的,图片最好是标准扫描,页面最好没有阴影,文档最好没有弯折。
机器看不懂真实世界,那就只能改造真实世界。
第二种路线,以文心为代表:让模型直接理解真实世界。
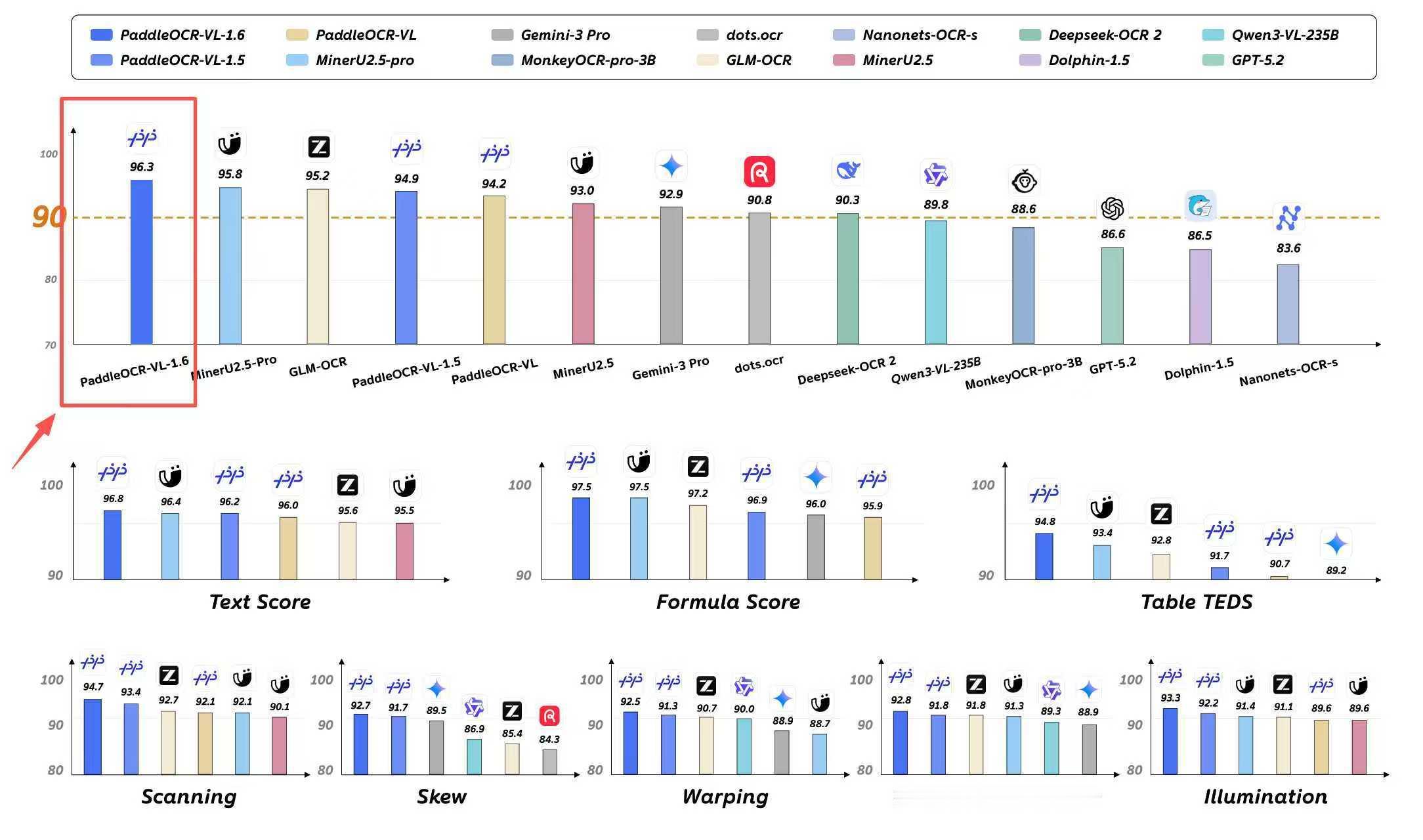
最近百度发布的PaddleOCR-VL-1.6,走的就是这条路。
它在OmniDocBench v1.6权威评测中,准确率达到96.3%,综合性能全球第一,超越Gemini-3-Pro、GPT-5.2、MinerU-2.5-Pro。
在面向真实复杂场景的Real5-OmniDocBench评测中,总指标达到93.19%,较Gemini-3-Pro提升近4个百分点。
更关键的是,它能直接理解真实世界的复杂场景,弯折页面、倾斜文档、手机拍照、光照变化,无需预处理就能识别。
PaddleOCR基于文心大模型训练而来,是文心大模型多模态能力的重要部分。
它不只是一个OCR工具,而是文心大模型获取现实世界知识的数据入口,图书馆里的纸质书、企业文档、档案资料、古籍文献、手机拍摄的文档,都能成为文心训练的养料。
而且PaddleOCR的GitHub Star已经突破79.2K,超越谷歌开源的Tesseract OCR,成为全球最受开发者欢迎的开源OCR项目之一。
4
所以,为什么各家模型厂商都在布局OCR?
原因很简单,随着大模型竞争进入数据争夺阶段,OCR正在成为AI连接现实世界的关键基础设施。
互联网数据只是知识来源的一部分,大量高质量知识其实存在于图书馆里的纸质书、企业内部文档、历史档案资料、古籍文献等等,这些都是大模型未来的重要知识入口。
而PaddleOCR作为文心衍生模型,支持超100种语言识别,用户覆盖170多个国家和地区,站在了这轮大模型竞争的关键位置上。
带来的结果是:文心多模态能力也非常强。
因为PaddleOCR为文心打开了海量真实世界数据的入口。
Anthropic拆书事件最值得讨论的,不是拆了多少书,而是两种AI训练哲学的分化——让世界适应模型,还是让模型理解世界。
Anthropic选择了前者,百度文心+PaddleOCR正在走后者。