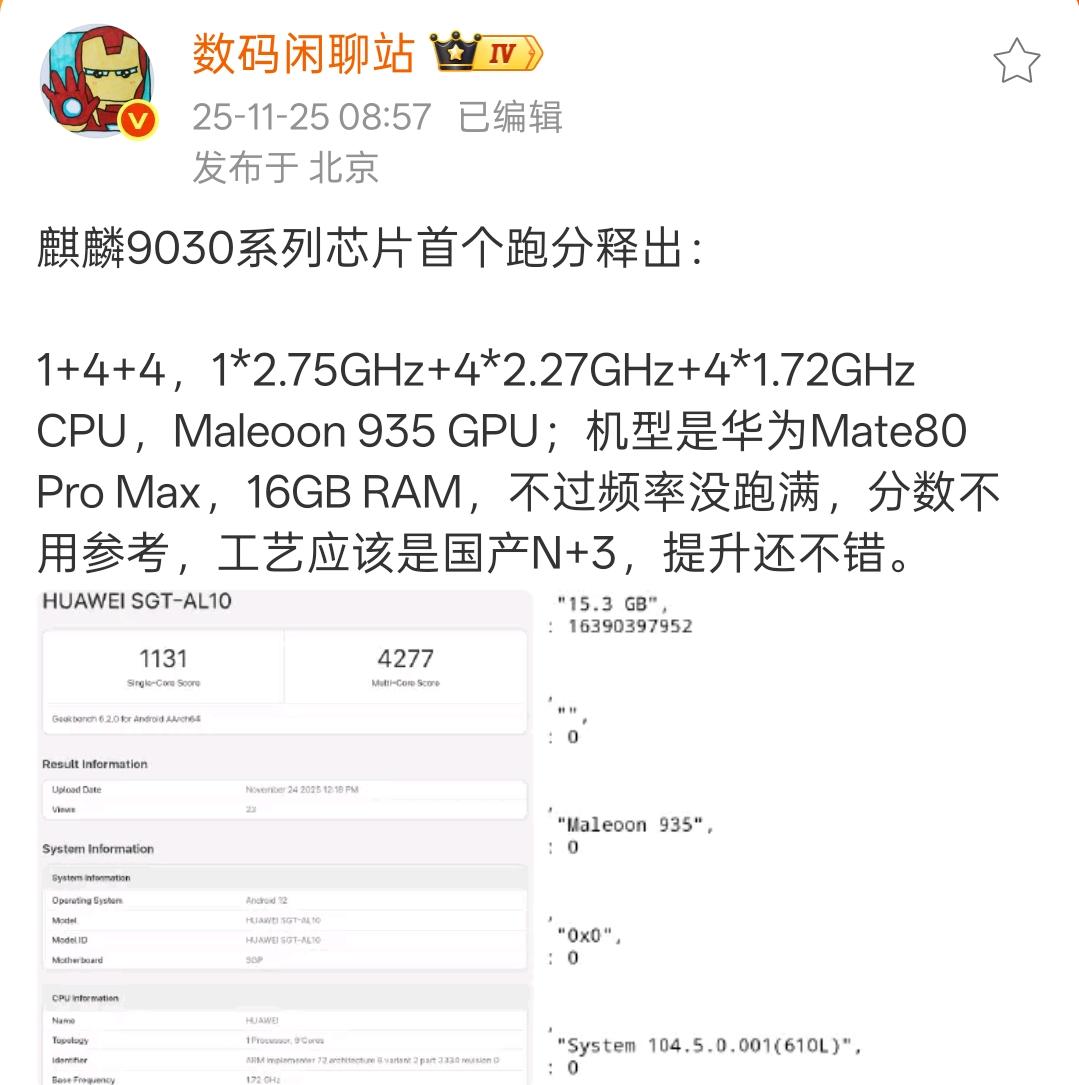
绝大多数人被英伟达(Nvidia)股价的狂欢蒙蔽了双眼,认为GPU是AI时代的终极答案。但事实可能恰恰相反。谷歌刚刚发布的Gemini 3在各项基准测试中霸榜,而训练这个史上最强模型的,并非英伟达的GPU,而是谷歌自研的TPU。
这不仅仅是两家公司的商业竞争,本质上,这是“全能工匠”与“流水线”在物理极限上的一次碰撞。

为什么英伟达的GPU在面对谷歌TPU时,会显得“笨重”?要理解这一点,我们不需要复杂的计算机架构图,只需要理解一个热力学概念:数据搬运的能耗。
你可以把英伟达的GPU想象成一个塞满了成千上万个顶级大厨的超级厨房。这些大厨(CUDA核心)全是通才,左手能做精美的图形渲染(切菜),右手能搞科学计算(炒菜)。
但这个厨房有一个致命的架构缺陷——冯·诺依曼瓶颈。
在GPU的传统架构里,工作流程是这样的:
几千个大厨听到指令。
所有人同时冲向巨大的冰柜(内存/显存)去拿一颗葱。
跑回案板切一刀。
再跑回冰柜把葱放回去。
如果需要切第二刀,重复上述过程。
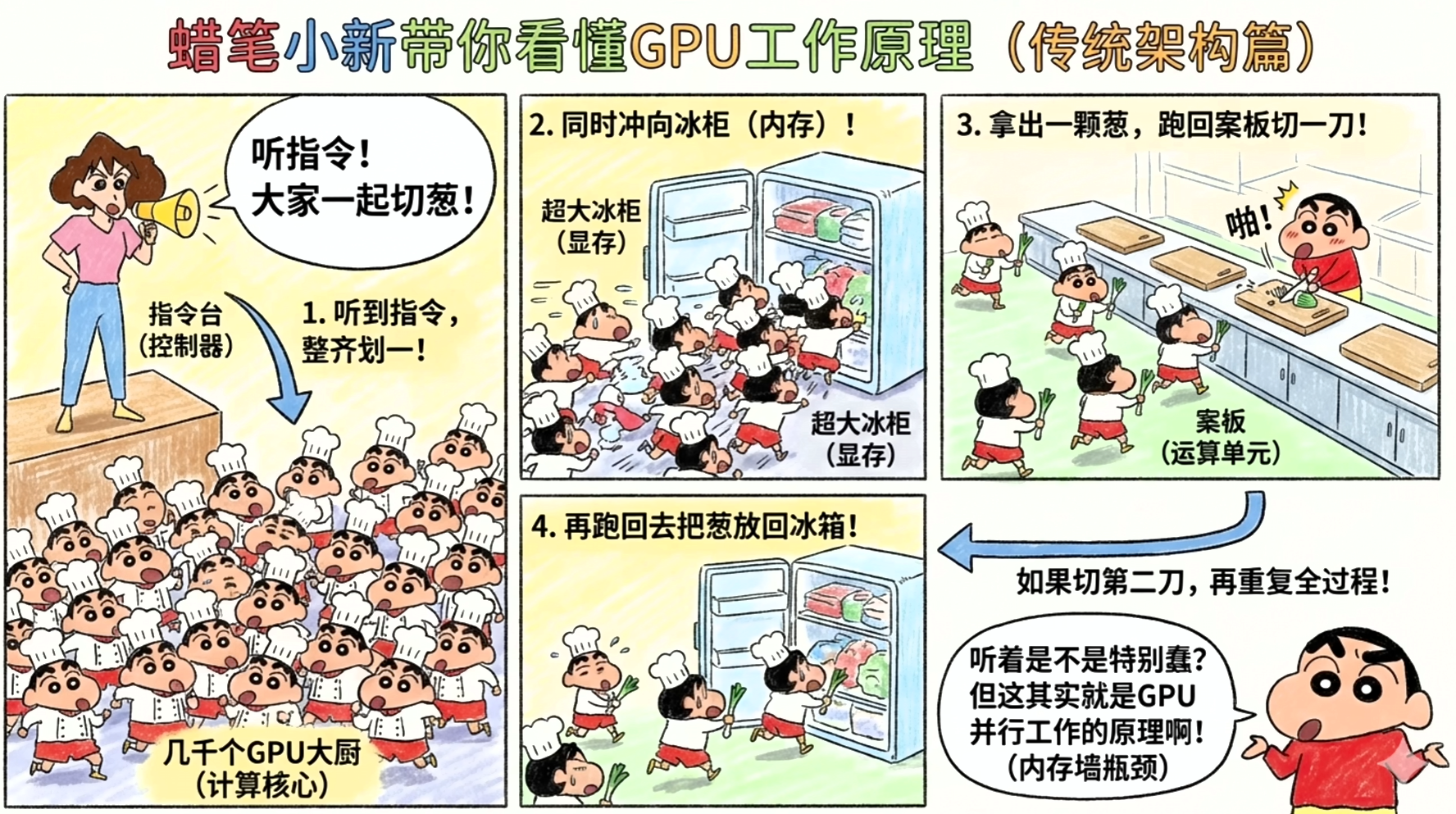
听起来是不是很荒谬?但这正是GPU并行工作的原理。这些“大厨”在大部分时间里,并不是在计算(切菜),而是在内存和计算单元之间进行疯狂的“折返跑”。
在物理学上,这种信息的移动是有代价的。 数据中心的风扇呼呼作响,电表蹭蹭上涨,大部分能量并没有用来产生智能,而是变成了废热。这就是熵增。
谷歌的TPU(张量处理单元)做了一个极端的减法。
TPU是一个严重的“偏科生”。它不会渲染游戏画面,不能做通用计算,它从诞生那天起只做一件事:矩阵运算。因为目标单一,谷歌为它设计了一种名为“脉动阵列”(Systolic Array)的架构。
这名字听起来很玄幻,但原理极度简单,它就是数据层面的流水线。
在TPU里,数据像血液一样流动。第一个处理单元切完一刀,不跑回冰柜,而是直接顺手递给旁边的第二个单元;第二个切完递给第三个……数据在芯片内部一步步被榨干价值,中间完全不需要访问内存。
这就叫数据复用(Data Reuse)。

这意味着,做同样的算术题,英伟达的大厨跑了十趟冰柜,累得气喘吁吁(高能耗);而谷歌的流水线工人在原地动动是指头就搞定了(低能耗)。在单芯片时代,这点电费微不足道;但当你把几万颗芯片连在一起,日夜不停地训练像Gemini 3这样的大模型几个月时,能耗的差异就变成了天文数字的成本差异。
74%的“过路费”与谷歌的阳谋物理层面的降维打击,最终会映射到商业层面的血腥屠杀。
华尔街现在看着英伟达的财报狂欢,但谷歌在看这财报时,看到的是巨大的套利空间。我们来看一组核心数据:英伟达的毛利率约为74%。
这意味着什么?意味着微软、Meta、亚马逊每花100块钱买英伟达的卡,只有26块钱是付给了台积电的代工费和物料成本,剩下的74块钱,是交给黄仁勋的“AI时代过路费”。
如果你是谷歌,你要训练Gemini 3:
方案A(用英伟达): 你必须顶着74%的溢价烧钱,这是极高的资本支出(CapEx)。
方案B(用自研TPU): 芯片设计自己搞,只需付给台积电代工费。这74%的利润,全部留在了自己兜里。
这就是为什么谷歌敢宣称其TPU算力性价比是GPT-4o的24倍。这不完全是算法的奇迹,这是商业模式对物理成本的极致压榨。谷歌是在贴着成本价跑,而竞争对手是在顶着高昂的溢价跑。
那么问题来了,既然TPU这么便宜又好用,谷歌为什么不把它像显卡一样卖给大众?
这正是谷歌最高明、也最“鸡贼”的地方:把肉烂在锅里。
谷歌不卖铲子(芯片),它卖的是“挖洞服务”(云算力)。英伟达作为硬件厂商,必须把铲子做得通用,还得维护庞大的销售渠道。而谷歌的策略是:想用TPU?没问题,来Google Cloud租服务器。
这一招极其凶狠:
广告效应: 用Gemini 3的强悍性能作为TPU的最佳广告(Look,最强模型是用TPU训出来的)。
客户锁定: 吸引Anthropic、Midjourney等头部玩家进入谷歌云生态。
避开锋芒: 避开了英伟达最坚固的护城河——CUDA。
英伟达真正的壁垒不是芯片,而是过去15年几百万程序员用一行行代码堆出来的CUDA软件生态。这道“叹息之墙”让无数想造芯片的公司望而却步。但谷歌通过“只租不卖”的云服务模式,在云端屏蔽了底层硬件的差异,让用户在不知不觉中绕过了CUDA的壁垒,直接使用TPU的算力。
4. 结语:进化的宿命我们正处在一个计算架构大迁徙的前夜。
这不仅是谷歌与英伟达的战争,更是通用计算与专用计算的周期律。在生物学中,单细胞生物往往是全能的,但随着生命体变得复杂,必然演化出心脏、肝脏、大脑等高度专用的器官。
英伟达的GPU就是那个全能的单细胞,在AI爆发初期,它的灵活性至关重要。但在AI模型参数迈向万亿、十万亿级别的今天,能源效率和成本控制成了生死的关键。这时候,像TPU这样高度进化的“专用器官”,在物理定律的加持下,展现出了难以抗拒的优势。
英伟达并没有输,它依然占据着90%的市场,CUDA依然坚不可摧。但谷歌正拿着一把名为“能效比”的铲子,试图挖开这道墙角。
对于我们人类而言,这或许是一个启示:当一个行业发展到极致,竞争的本质不再是“谁能做更多的事”,而是“谁能以更低的熵增,完成最重要的事”。
我是樗散生,不懂这个“樗”字怎么读,你也可以叫我废柴兄,我们下期见。