【名字只写YY藏伏笔?百度新开源OCR,吃瓜停不下来】
百度最近真的有点不一样,6月22号一大早,一个叫Unlimited OCR的模型悄悄挂上了HuggingFace和GitHub,百度出品,直接开源,但圈内人读完技术报告全在问同一个问题:作者名单里那个叫“YY†”的技术总监,到底是谁?
报告的核心贡献者列了三个人。前两位Youyang Yin和Huanhuan Liu,用的都是真名,很正常。唯独技术总监的位置,只挂了“YY”两个字母。在一篇正经技术报告里,这种操作属实不多见,反而像故意留的扣子。
再往下翻GitHub的致谢栏,更有意思了。排在最前面的两个致谢对象,是DeepSeek-OCR和DeepSeek-OCR-2。一个新模型开源,把另一个公司的项目放在这么显眼的位置感谢,这关系肯定不一般。顺着这条线往回看,DeepSeek OCR从一代到二代,核心作者始终就是那几个人,一个小团队从零做起来的。国内OCR圈子本来就不大,能做出这种级别突破、还对DeepSeek OCR架构有亲手做过级别熟悉的,一只手数得过来。
更微妙的是整篇报告的写法。上来不讲性能不讲指标,直接从认知层面切入、故事感拉满的行文风格,以前基本是DeepSeek技术报告的招牌特征。再加上今年4月DeepSeek-V4报告末尾那10个带星号的离职名字,有些线索好像慢慢对上了。
当然,YY到底是谁,现在没人能给结论,纯属猜测。
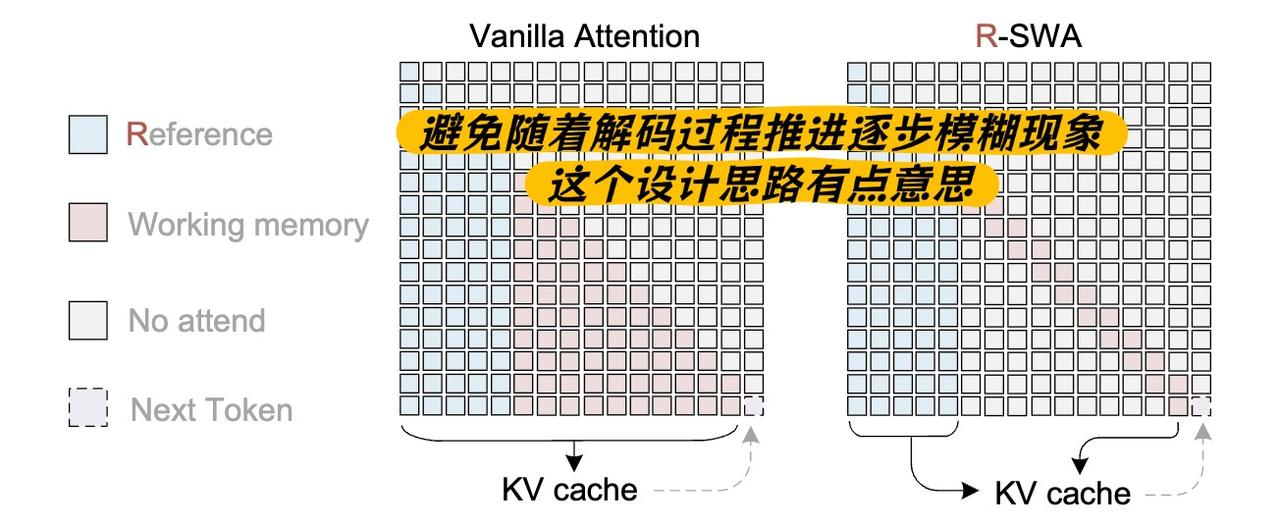
但模型本身确实挺有想法的。它解决的问题是:为什么现在OCR一次只能处理几页文档?因为传统做法是逐页扫描、每页清零记忆,相当于不断重启。Unlimited OCR的思路是模拟人类的工作记忆状态,用了一种叫参考滑动窗口注意力的机制,显存始终保持恒定,不会越跑越胀,一次前向推理就能转录几十页文档。
百度这波操作,从开源节奏到人才布局都透着一股新气象。文心后面还有啥动作,值得蹲一蹲。